
탐색적 데이터 분석이란?
데이터의 특성과 구조를 파악하기 위해 다각도로 분석하는 활동을 의미합니다.
시각화를 통해 구조를 파악해 보는 것 뿐만 아니라 상관 분석과 t-검증 등 통계적 기법을 활용합니다.
탐색적 데이터 분석을 하면 예측하고자 하는 종속 변수. 즉, 타깃 변수를 예측하기 위해 어떤 속성이 영향을 미치는지 알 수 있습니다.
뇌졸중(Stroke)발병 요인 중 중요한 변수는 무엇인가?
타깃 속성이란 예측하고자 하는 속성을 의미하며 탐색적 데이터 분석을 하는 목적이 되는 변수입니다. ‘종속 변수’라고도 합니다.
타깃 속성(=종속 변수) : stroke \\ \\ 타깃 변수 값 : 발병한 적 있으면 1, 아니면 0
타깃 속성(=종속 변수) : stroke \\ \\
타깃 변수 값 : 발병한 적 있으면 1, 아니면 0
탐색적 데이터 분석을 하는 목적은 타깃 속성에 영향을 미치는 속성을 찾아 나가는 것입니다.
지금부터 한 단계씩 해보도록 하겠습니다.
데이터 불러오기
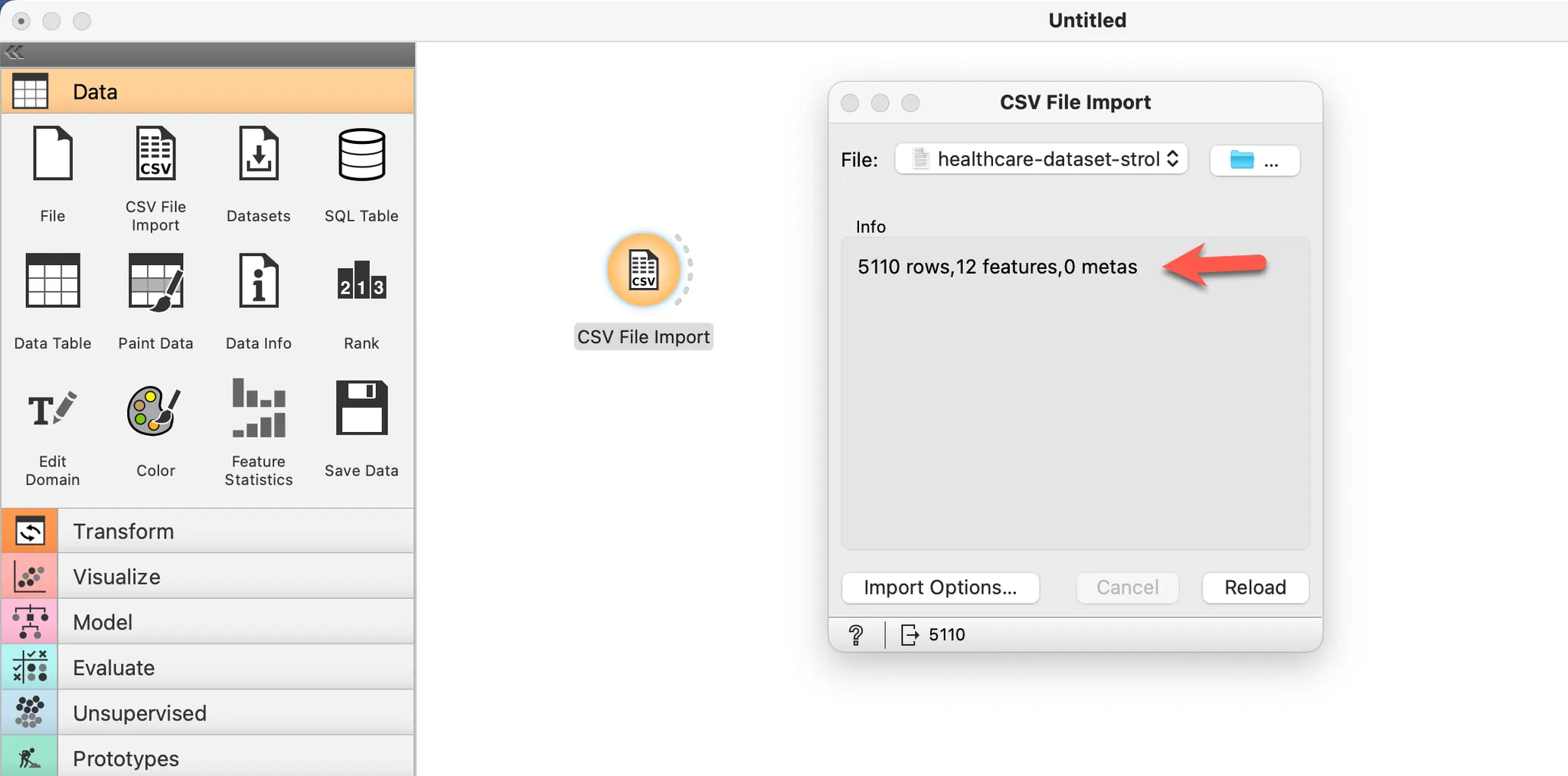
결측값 확인하기
Data Table 위젯을 통해 데이터를 살펴 보면 12개의 속성, 전체 데이터의 0.3%가 결측값이라는 것을 알 수 있습니다.
어떤 속성에 결측값이 있을까요? Feature Statistics 위젯을 이용하면 알 수 있습니다.
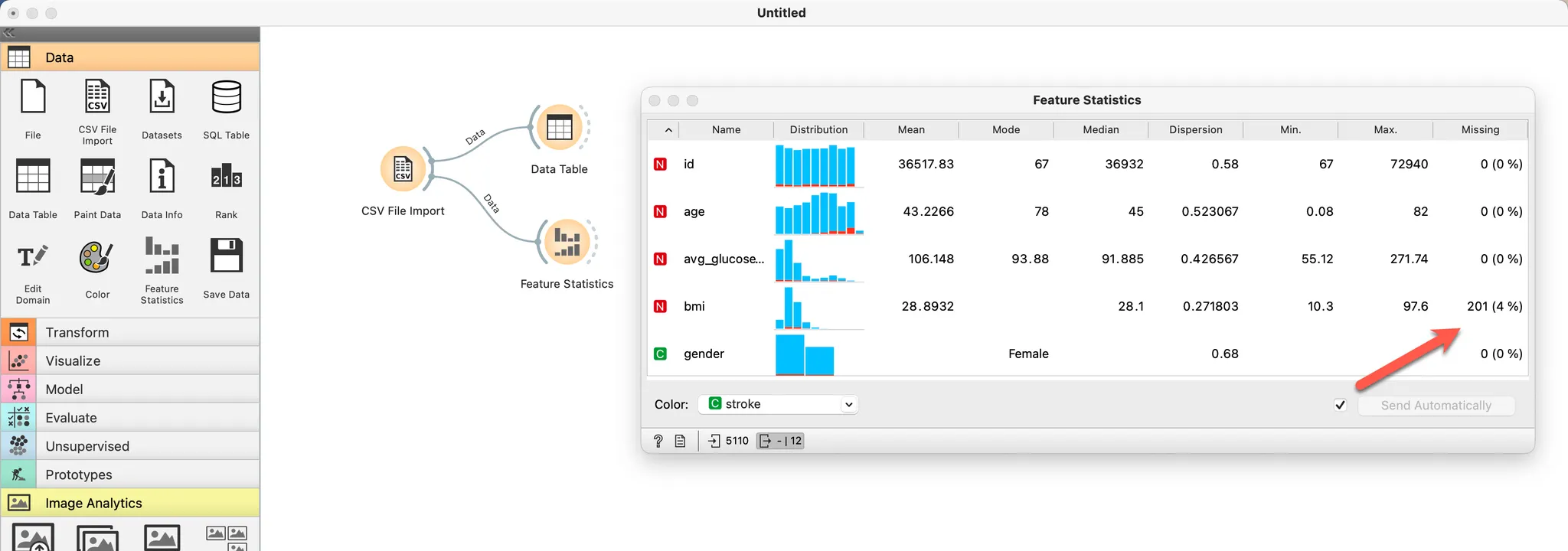
bmi 속성이 결측값을 가지고 있습니다.
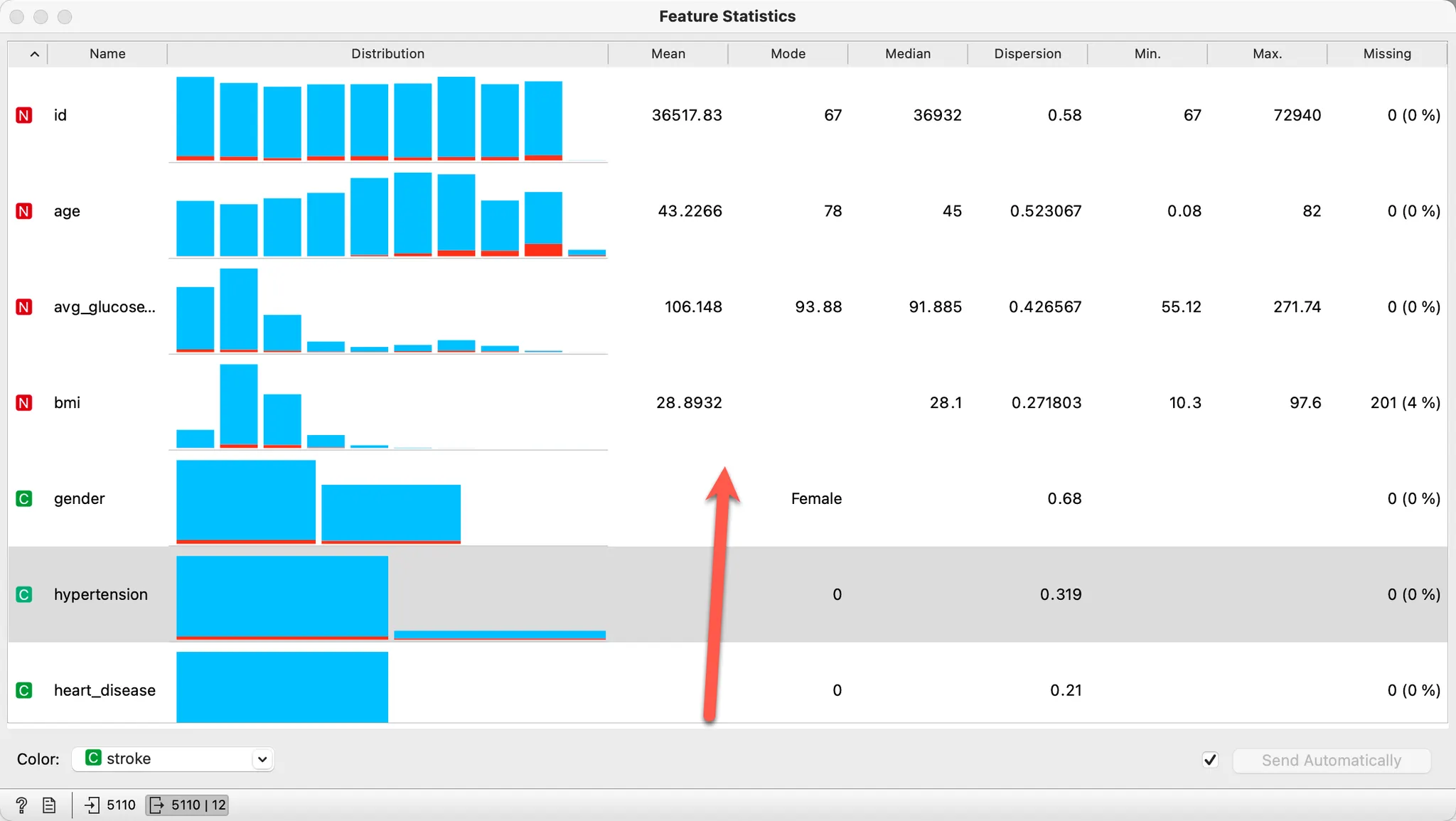
숫자형 속성은 N으로 표시 되고, 통계값도 함께 확인할 수 있습니다.
(C로 표시된 속성은 범주형 속성입니다.)

나이(age)의 최소값을 보면 0.08세로 되어 있습니다. 의학적으로 어린 아이에게도 뇌졸증이 발생할 수 있습니다. 하지만 지금 다루는 내용은 성인 대상 분석을 하는 것으로 한정지으려고 합니다. 따라서 18세 이하는 분석에서 제외합니다.
타깃 변수 분포 살펴보기
Distributions 위젯으로 분포를 살펴보겠습니다.
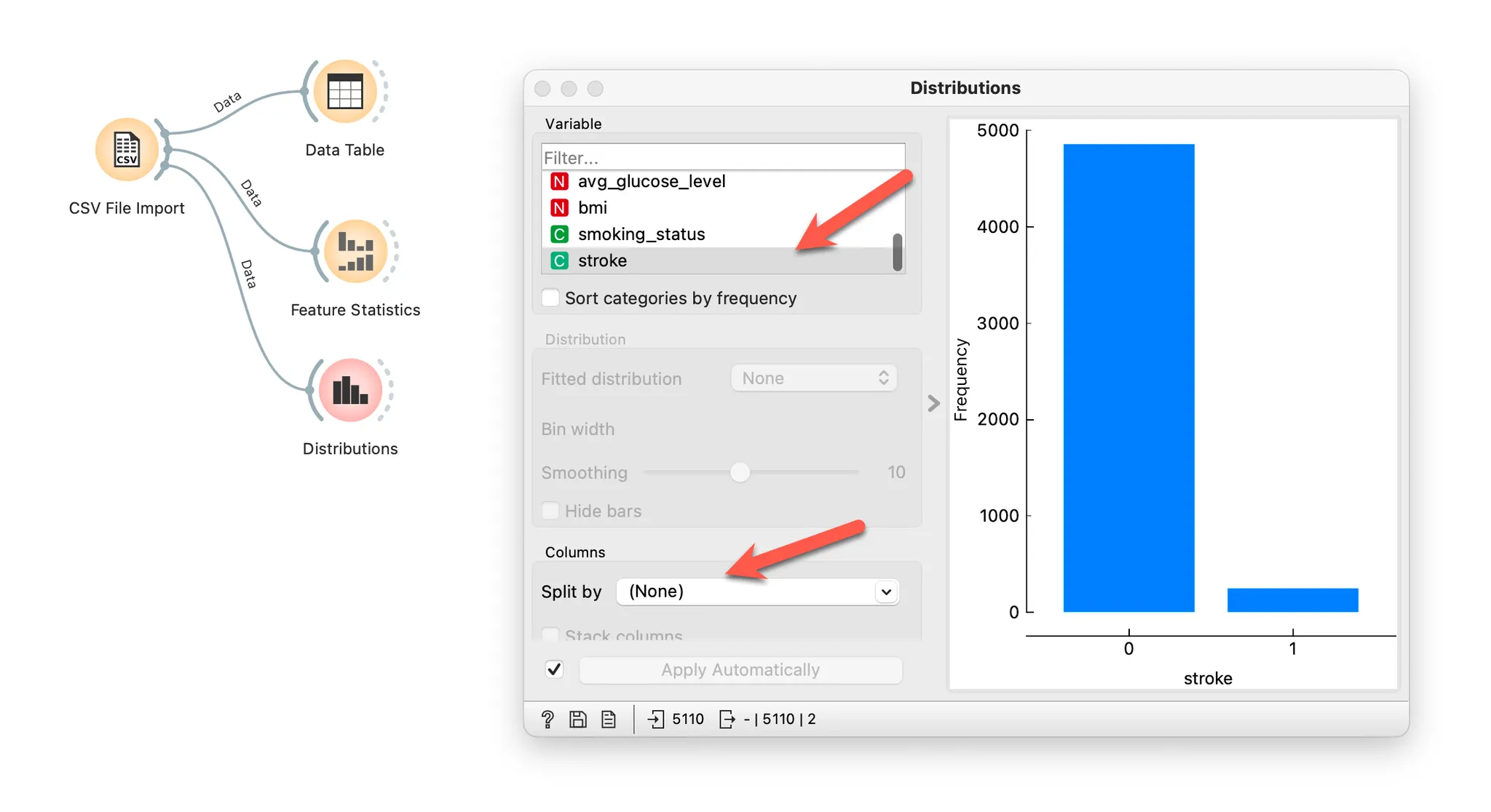
0이 많은 것을 알 수 있습니다.
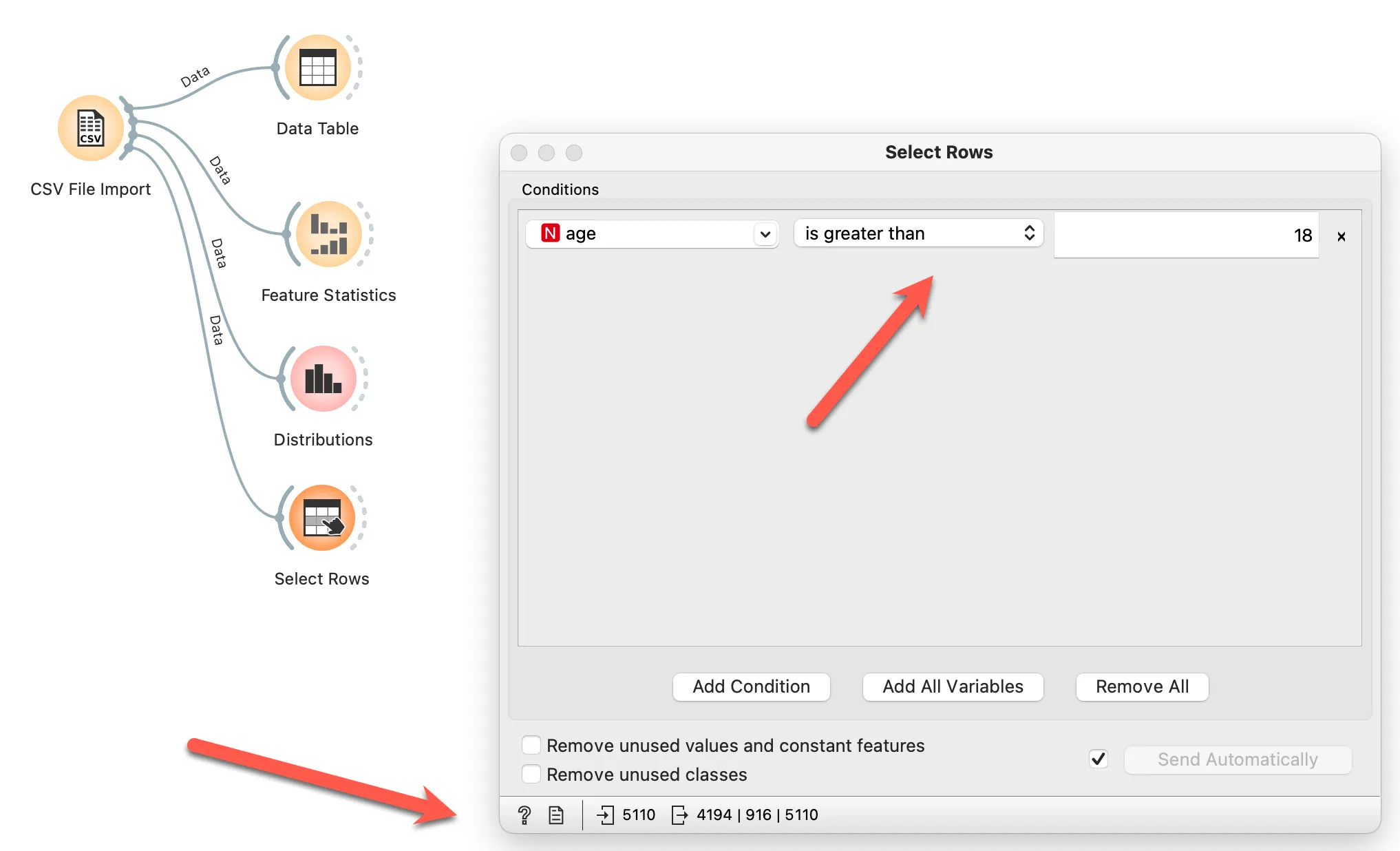
결측값은 반드시 제거해야 하는지 의문이 들 수 있지만 이는 정답이 아닙니다. 제거할 수도 있지만 여기에서는 50% 기준으로 넘지 않으므로 다른 조치 없이 진행하도록 하겠습니다.
이후, 다음과 같은 순서로 진행합니다. 이제부터는 통계적 수치를 해석하는 과정이 필요합니다.

속성별 정규분포를 따르는지 확인하기
숫자형 변수를 체크하기 위한 통계량은 왜도와 첨도가 있습니다.
(오렌지3에서는 이 값을 제공하는 기능은 없습니다. 파이썬에서는 skew, knutosis명령어로 확인할 수 있습니다.)
왜도의 허용 가능한 범위는 +- 3 이하, 첨도는 +-10 이하입니다.
범주형 변수는 도수분포표를 확인합니다.
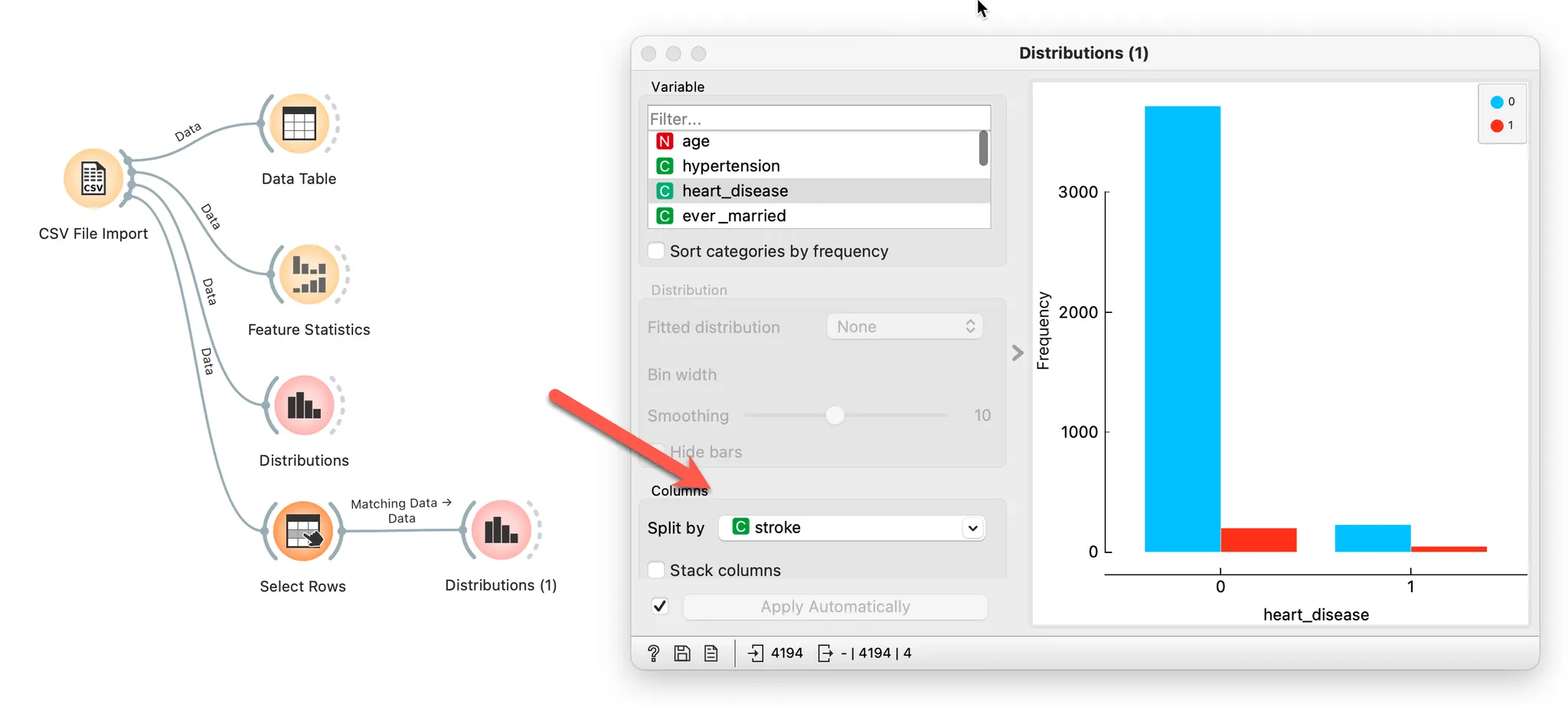
타깃인 stroke를 Split by로 설정해 놓은 후에 속성들의 분포를 살펴 봅니다.
이상값 제거하
이상값 제거는 숫자형 변수에서만 합니다.
극단적인 이상값은 분석 결과에 왜곡을 가져올 수 있기 때문에 제거해야 합니다. 그럼 어떤 값을 이상값으로 정하게 될까요?
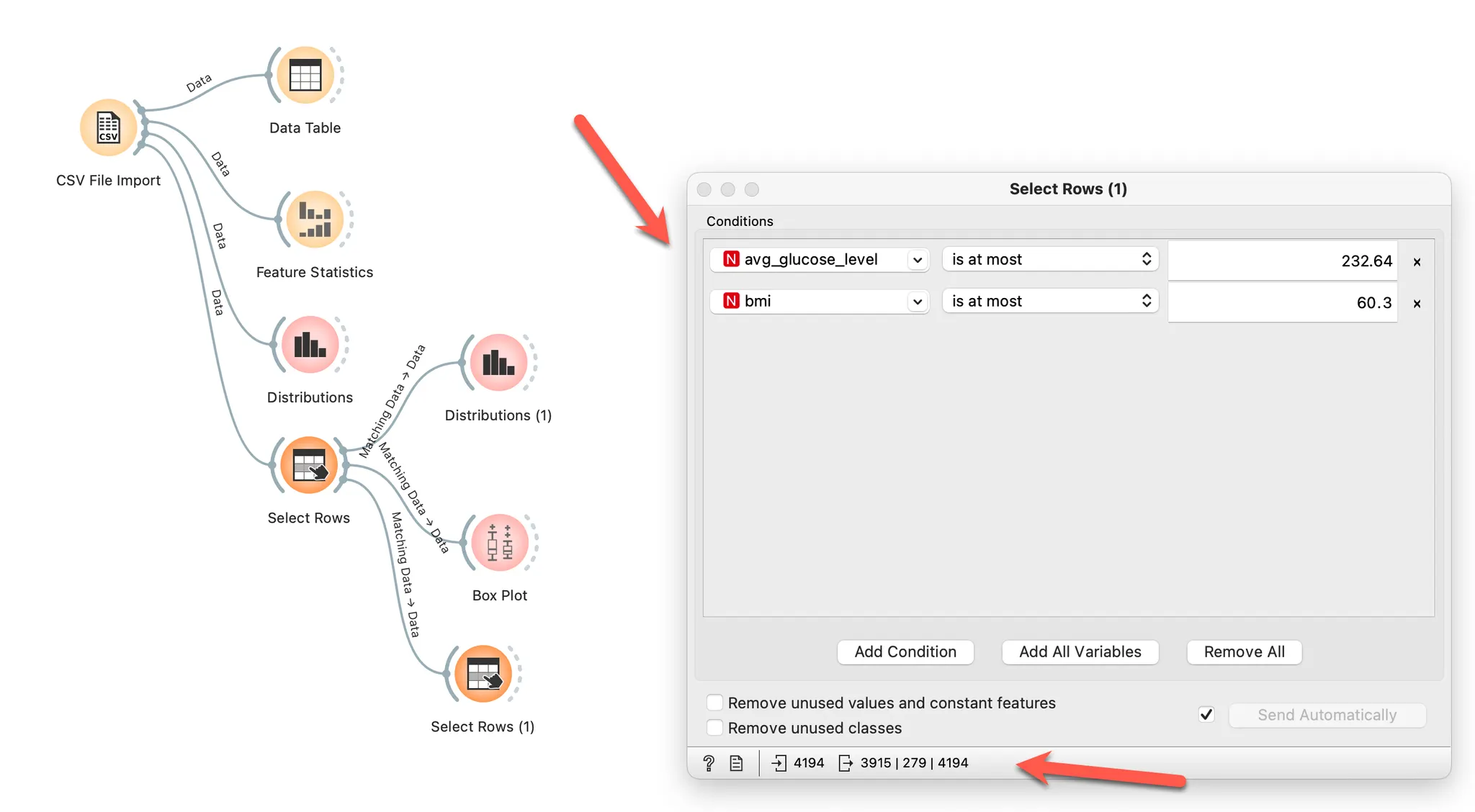
상자 그림 해석하기 : Outliers가 이상값에 해당한다.
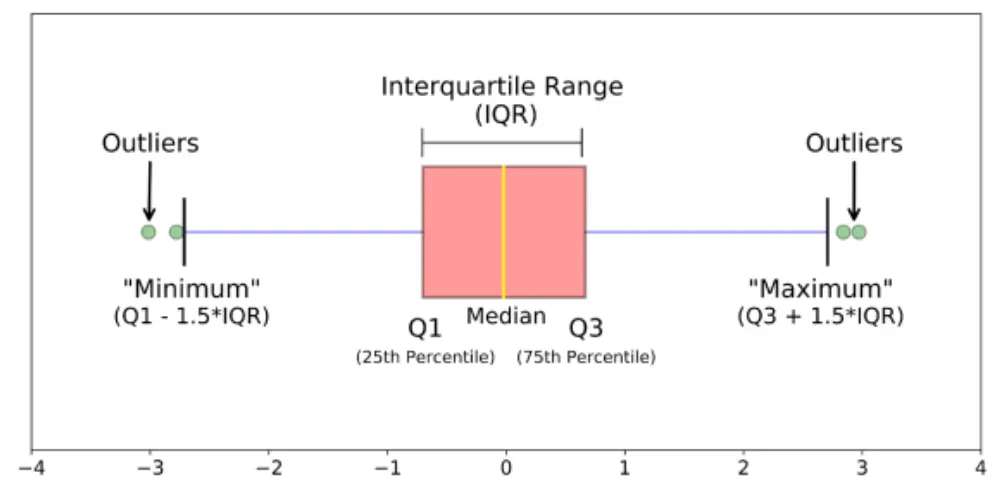
(1Q-3.0IQR) 미만과 (1 Q+3.0IQR) 초과제거 (경우에 따라 3.0 대신 1.5로 계산)
예를 들어, 체질량 지수를 보면 IQR = 34.2-25.5 = 8.7 이며
공식에 따르면 이상값은 25.5 + 3.0*8.7 = 60.3을 초과하는 값이 됩니다. 이 값을 제거해야 합니다.
같은 방식으로 계산하면 평균 혈당치 232.64도 구할 수 있습니다.
상관계수 검토하기
상관계수란 두 변수의 선형 종속성을 나타내는 계수로, -1과 1 사이의 값을 갖습니다. 상관 관계가 없으면 값은 0입니다.
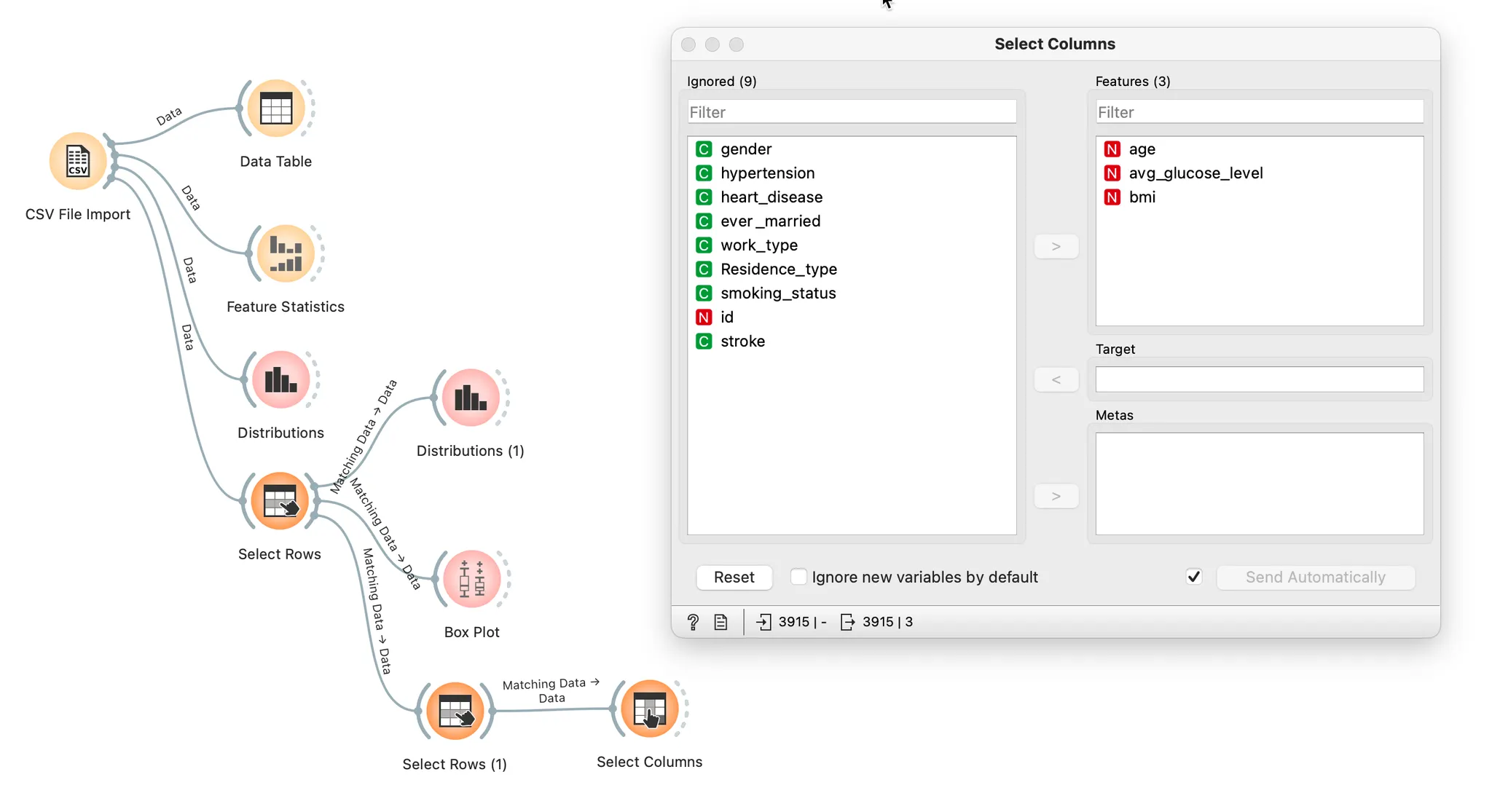
숫자형 변수에 대해 상관계수 검토를 합니다.
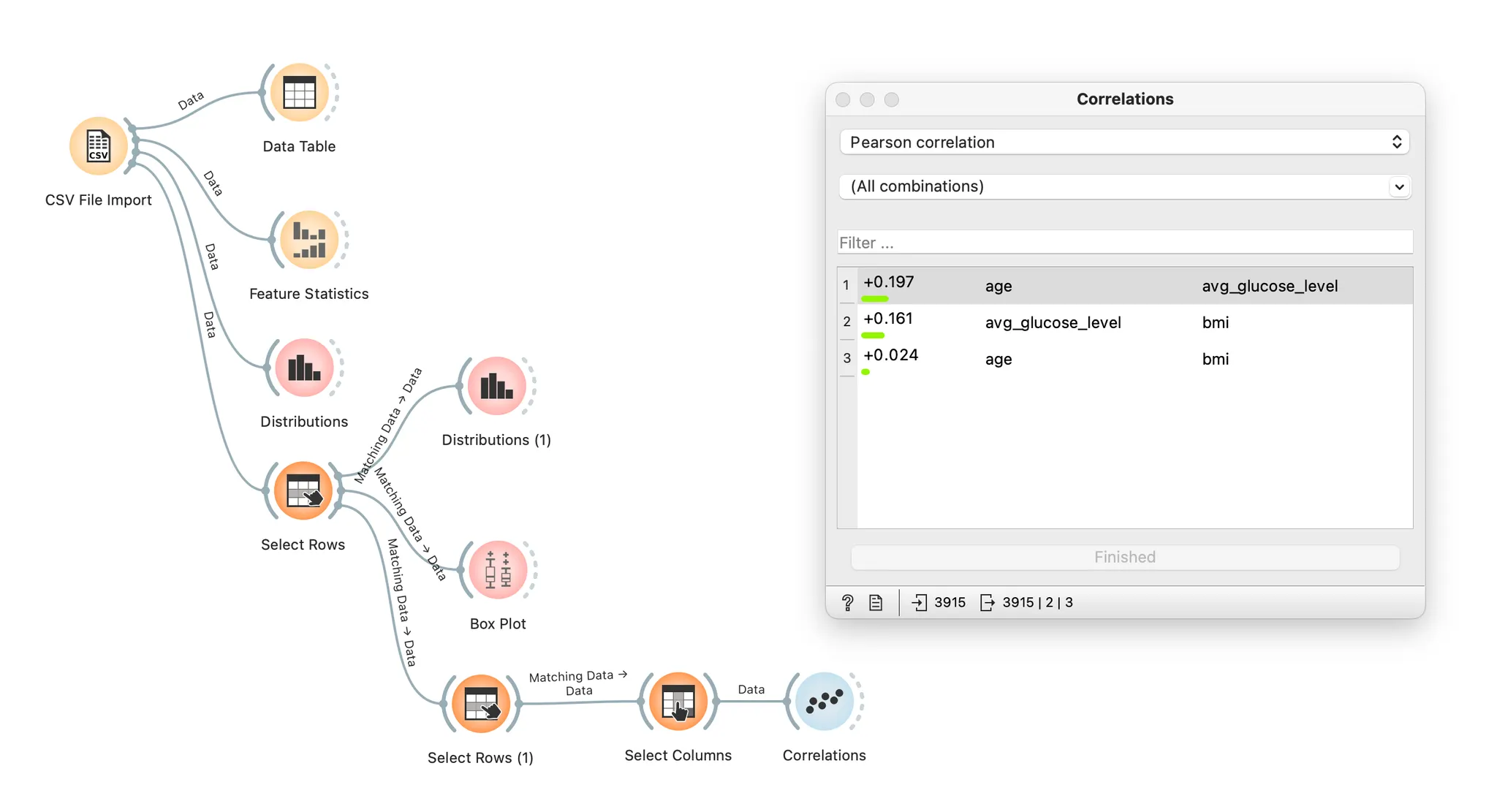
입력 변수 간의 상관관계가 높으면 회귀 모델의 결과가 왜곡됩니다. 이를 다중공선성(Multicollinearity)이라고 합니다.
상관계수의 절대값이 0.7 이상인 변수들을 제외하는 것이 좋습니다.
숫자형 컬럼 3개를 선택한 후 Correlations 위젯에 연결하여 결과를 살펴보니 세 변수 간의 상관계수가 각각 +0.197, +0.161, +0.024로 절대값이 모두 0.7미만입니다.
t-검정으로 확인하기
타깃 속성이 범주형일 때 t-검정을 하는 것이 의미가 있으며, 숫자형 변수에 대하여 실시합니다.
stroke 값이 그룹별 (0 or 1)로 평균에 차이가 있는 지를 알아보기 위해서 합니다.
샘플이 타깃 변수에 stroke에 의해 나뉘므로 이 경우는 독립 표본 t-검정 (student’s t)이라고 합니다.
평균이 통계적으로 유의미하게 다르다고 말할 수 있다면, 그 변수는 stroke에 영향을 미칠 가능성이 큽니다.
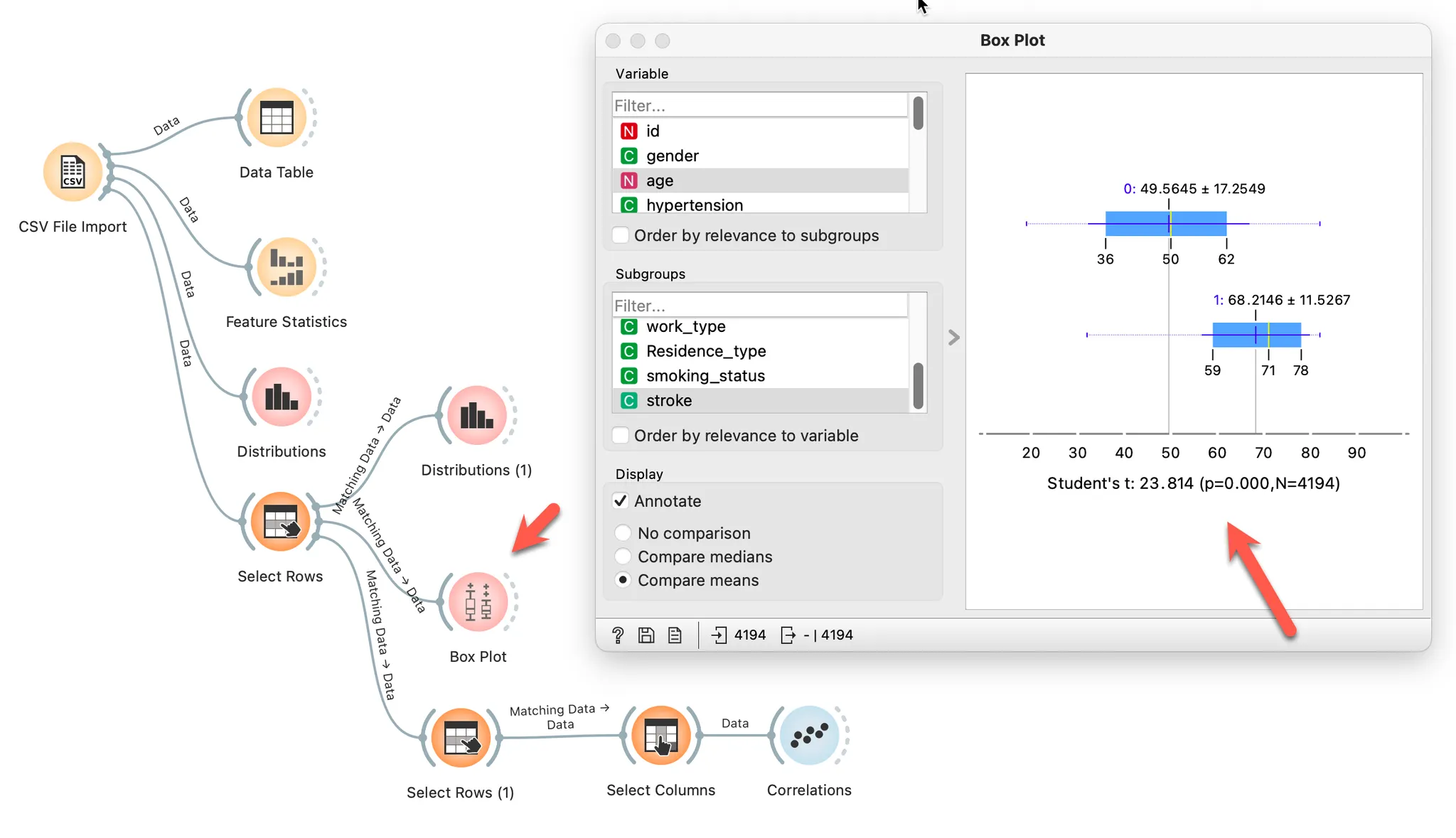
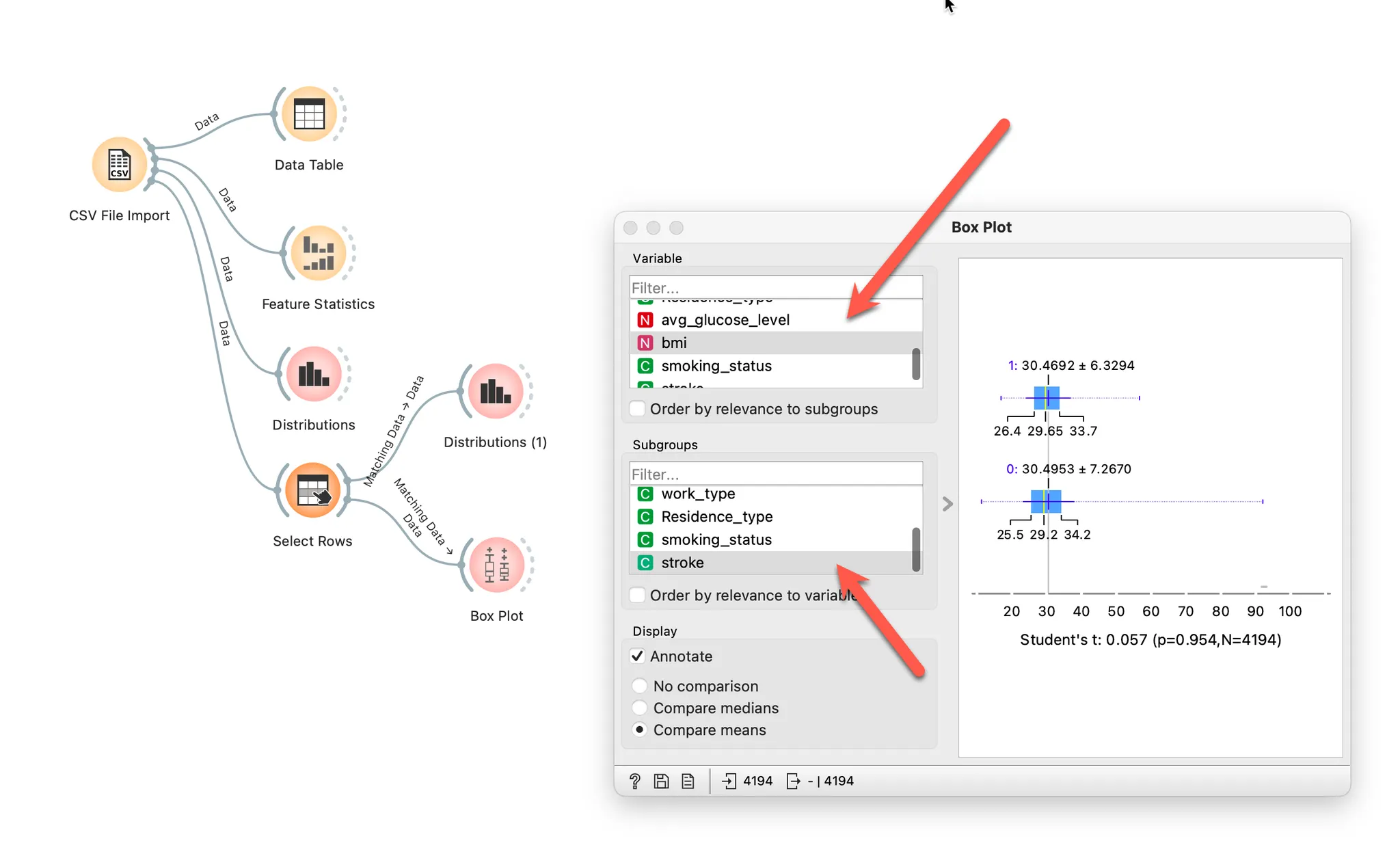
Box Plot위젯을 보면 해당 값을 알 수 있습니다.
P 값(P-value)을 보면 됩니다.
0.05보다 작으면 귀무가설(null hypothesis)를 기각할 수 있습니다.
즉, 두 그룹의 나이가 같다는 가설을 기각할 수 있습니다.
⇒ 즉, 두 그룹의 나이는 통계적으로 유의미하게 다르다라고 판단할 수 있습니다.
나이는 stroke에 영향을 미칠 가능성이 큰 속성입니다.
위의 그림에서 p값은 0.000 이므로 두 그룹의 평균 나이는 유의미하게 다르다고 볼 수 있습니다.
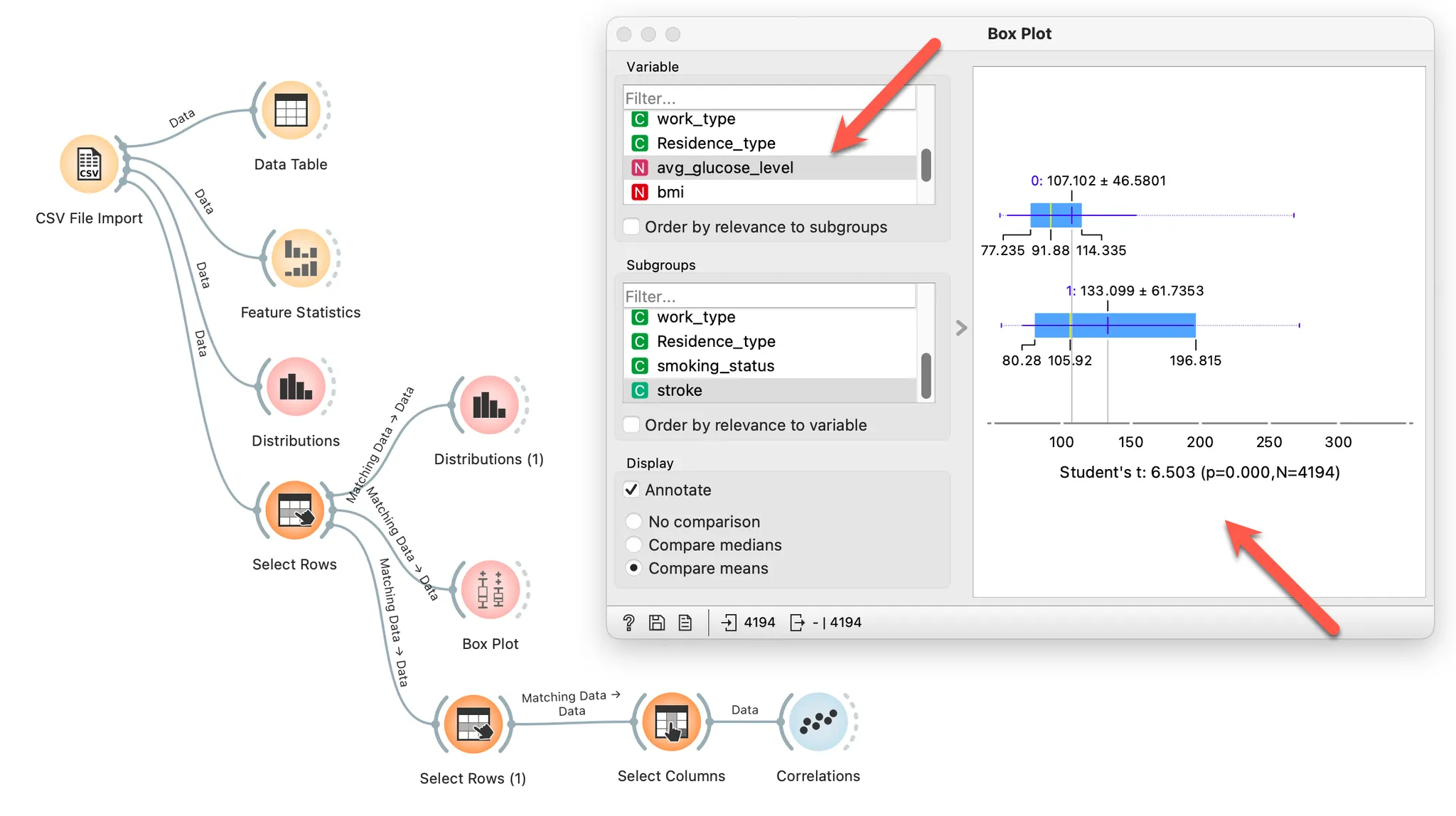
평균 혈당값의 평균은 유의미하게 다르기 때문에 타깃 속성 stroke에 영향을 미칠 가능성이 큰 속성입니다.
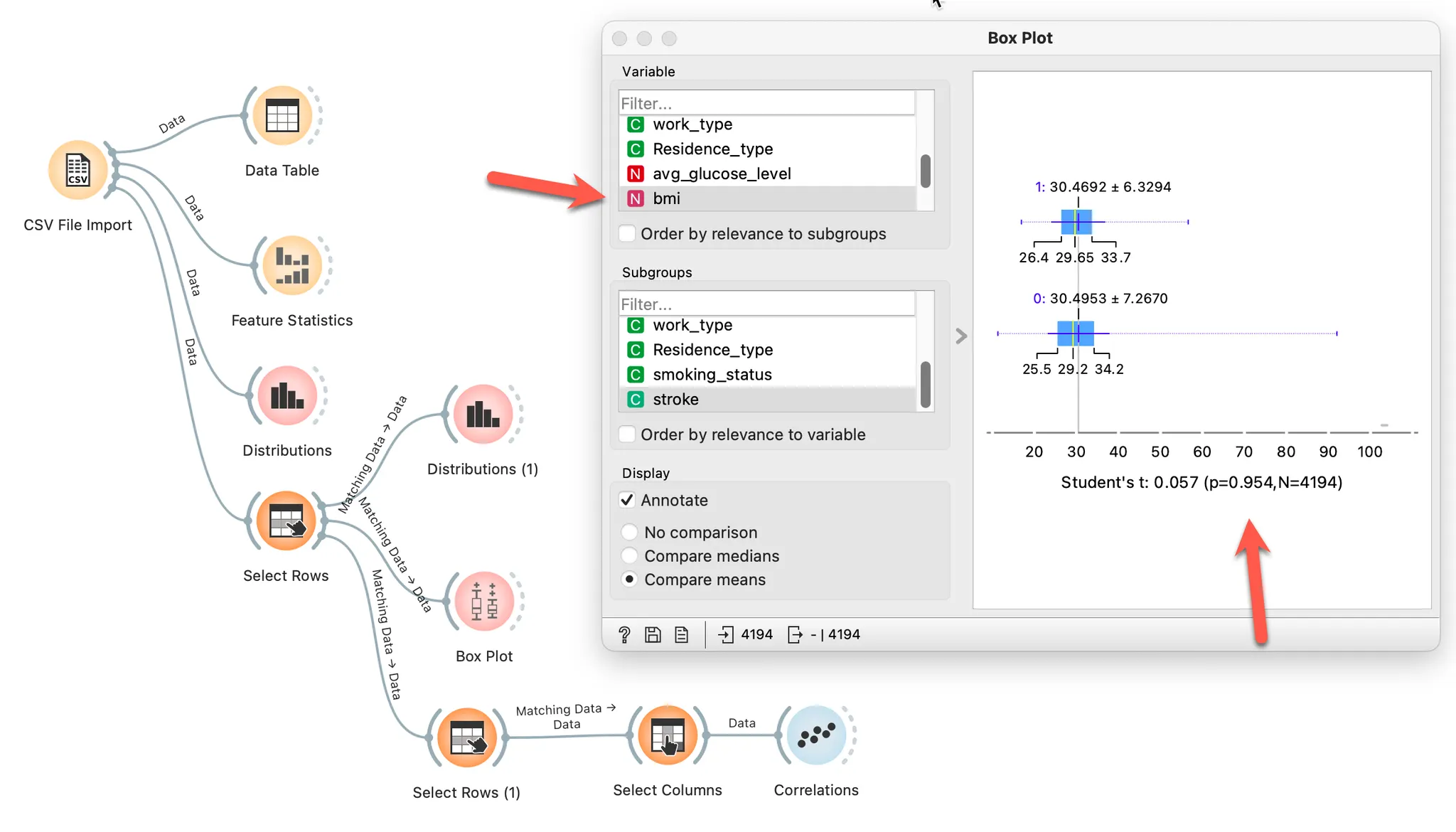
체질량 지수는 P값이 0.954로 0.5 보다 크므로 두 그룹의 유의미하게 다르다고 판단할 수 없습니다.
체질량 지수는 stroke에 영향을 미칠 가능성이 작다고 판단할 수 있습니다.
여기까지 탐색적 데이터 분석을 해 보았습니다.
결측값을 살펴보았고, 그림 상자를 이용해 이상치를 제거했습니다.
그리고 상관관계를 살펴보면서 속성간의 연관성을 살펴보았습니다. 이 때의 기준은 절대값 0.7이었습니다. t-검증을 통해 p-값의 귀무가설을 보았고, 이때는 0.05를 기준으로 판단하였습니다.
처음 질문으로 돌아가
뇌졸중(stroke)발병 요인 중 중요한 변수는 무엇인가?의 답을 찾으셨을까요?
체질량 지수를 제외한 나머지 속성들이 중요한 변수. 즉, 핵심 속성이 되겠습니다.
출처: 오렌지3 데이터 분석 with파이썬, 임선집 외 2인, 루비페이퍼