
1. 코퍼스와 텍스트 마이닝
코퍼스는 언어를 연구하는 각 분야에서 필요로 하는 연구 재료로서 언어의 본질적인 모습을 총체적
으로 드러내 보여줄 수 있는 자료의 집합을 뜻한다(출처: 위키백과). 이는 연구자나 데이터 과학자가
특정 목적을 위해 수집한 대량의 텍스트 문서들을 포함할 수 있으며, 이 데이터는 언어학적 연구, 정
보 검색, 기계 학습 모델 훈련 등 다양한 용도로 사용된다.
텍스트 마이닝은 코퍼스에 포함된 텍스트 데이터로부터 유용한 정보를 추출하고, 패턴을 발견하며,
지식을 도출하는 분석 과정이다. 이 과정에는 데이터 전처리(토큰화, 정규화, 불용어 제거 등), 데이터
탐색(워드 클라우드, 빈도 분석 등), 고급 분석(감성 분석, 토픽 모델링, 품사 태깅 등) 등이 포함된다.
코퍼스와 텍스트 마이닝의 관계를 살펴보면, 코퍼스는 텍스트 마이닝의 분석 대상이 되는 원시 데이
터의 집합으로, 텍스트 마이닝은 이 코퍼스를 분석하여 유의미한 결과를 도출해 낸다. 즉, 코퍼스는 텍스트 마이닝을 수행하기 위한 원료와 같으며, 텍스트 마이닝은 이 원료로부터 가치 있는 정보를 추출하는 공정이라고 볼 수 있다. 따라서, 텍스트 마이닝의 성공은 고품질의 코퍼스 구축에서 시작되며,
이 두 요소는 효과적인 언어 데이터 분석을 위해 서로 의존적인 관계에 있다고 할 수 있다.
2. 전처리하기
캐글 사이트에서 'BTS Lyrics and Spotify Data'라는 가사 데이터셋을 다운로드한다.
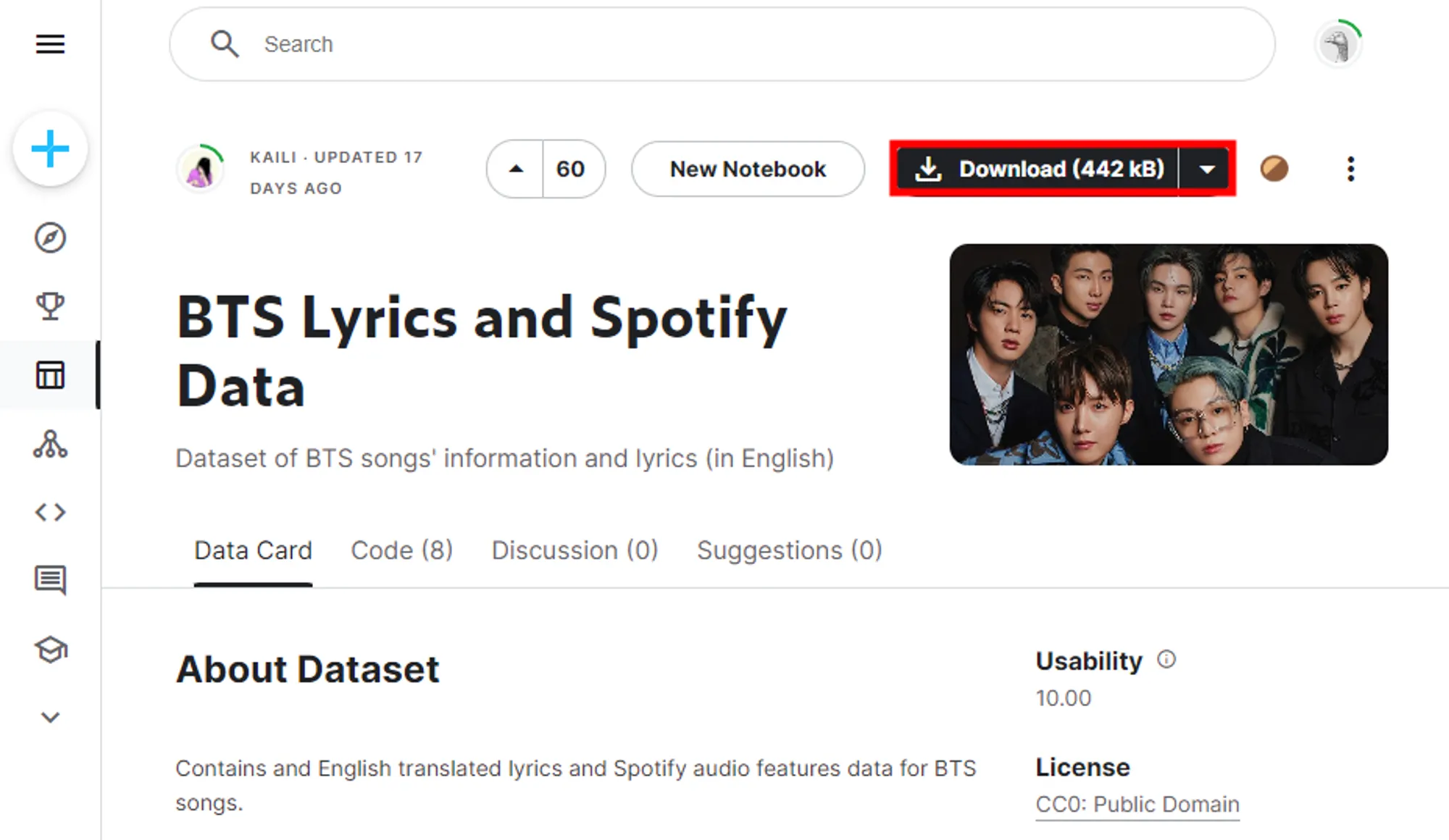

이 데이터셋은 Genius와 Big Hit에서 가져온 데이터를 사용하여 비공식적으로 만들어졌다. BTS의 24개 앨범에서 비롯된 트랙들에 대한 정보를 담고 있으며, 각 트랙을 고유하게 식별할 수 있는 숫자 ID, 앨범의 제목, 발매 날짜, 트랙 순서, 트랙 제목(한국어 및 영어), 영어 번역 가사 등을 포함한다. 또한, 숨겨진 트랙, 리믹스 여부, 특별 참여 아티스트, 수행 멤버, 트랙이 이전에 발매된 적이 있는지, 트랙의 언어, 전체 버전의 존재 여부 등에 대한 정보도 제공된다. 이 데이터를 통해 BTS의 음악과 가사에 담긴 메시지를 분석할 수 있으며, 특히 영어로 번역된 가사를 통해 음악이 전달하고자 하는 바를 더 깊이 이해할 수 있다.
텍스트 분석을 하기 위해 ‘Text’를 설치해야 한다.
[Options] - [Add-ons…]에 들어가서 ‘Text’를 선택한 후 다운로드한다.
Text Mining-Corpus 위젯을 끌어온 후 클릭하여 ‘bts_v13.csv’ 파일을 불러온다.

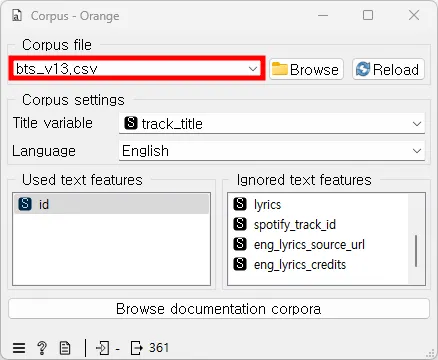
오렌지3의 [Corpus] 위젯을 사용하면, 표준화된 형식의 파일(예: Excel, CSV)에서 텍스트 데이터를 불러와 자동으로 코퍼스를 생성할 수 있다. 이 기능을 사용하면, 사용자는 단순히 데이터가 저장된 파일을 선택하기만 하면 된다. 그 후, 위젯은 선택된 파일의 내용을 분석하여 필요한 텍스트 데이터를 추출하고 이를 코퍼스 형태로 조직한다. 이 과정을 통해 사용자는 쉽고 빠르게 다양한 형태의 텍스트 데이터를 효율적으로 처리하고 분석할 준비를 할 수 있다.
text features에서 텍스트 분석에 사용될 기능들과 텍스트 분석에 사용되지 않을 기능들을 선택한다. (두 상자 사이에서 드래그 앤 드롭으로 변수를 옮기거나, 표시되는 순서를 변경할 수 있음)
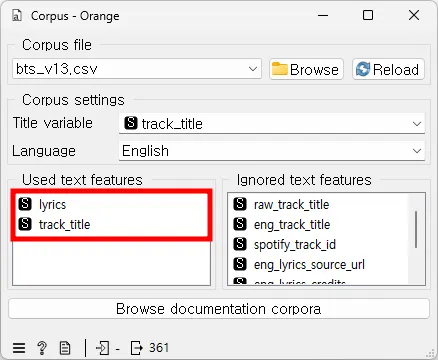
다음으로 [Corpus] 위젯을 [Corpus Viewer] 위젯과 연결한다. Corpus Viewer에서 BTS 데이터셋의 내용을 검토할 수 있다.
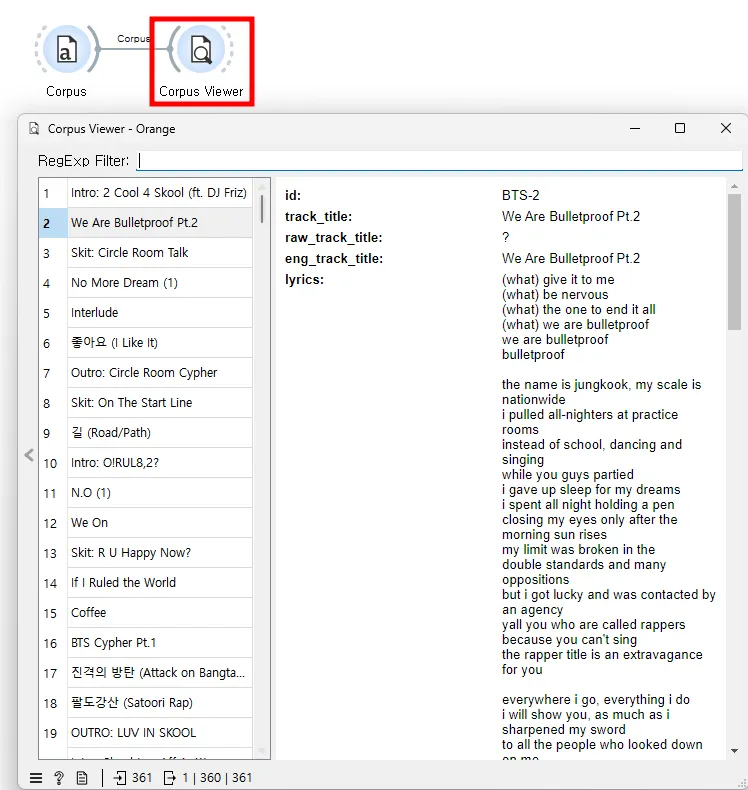
데이터셋을 [Corpus Viewer]로 확인한 후에는 [Preprocess Text] 위젯을 연결한다.
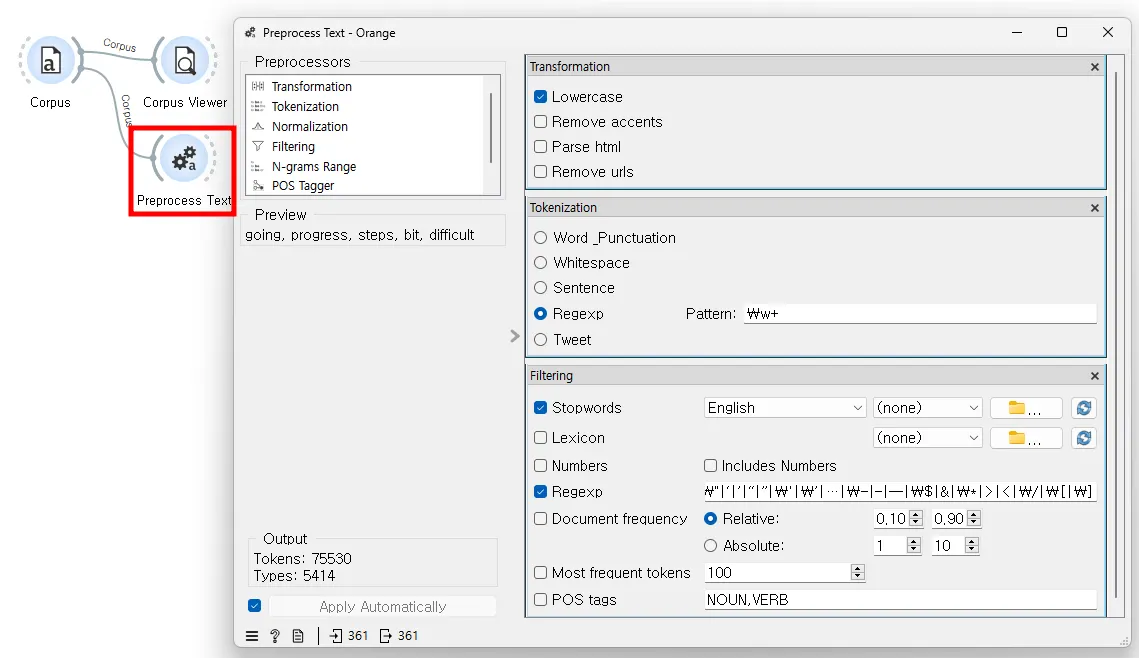
[Preprocess Text] 위젯은 텍스트 데이터를 분석 전에 준비하는 데 사용되며, 주된 목적은 불필요한 정보를 제거하고 데이터를 분석에 적합한 형태로 표준화 및 구조화하는 것이다. 이를 통해 데이터 분석의 정확도와 효율성을 높일 수 있다. 우리는 이 과정에서 'Transformation', 'Tokenization', 'Filtering' 세 가지 프리프로세서를 사용할 예정이다.
<Preprocess Text 항목별 설명>
•
Transformation: 텍스트 변환은 원본 텍스트를 수정하여 표준화하는 과정이다. 예를 들어, 모든 텍스트를 소문자로 변환하거나, 필요 없는 구두점을 제거하는 등의 작업이 포함된다. 이러한 변환은 분석 과정에서 동일한 단어가 다른 단어로 인식되는 것을 방지하고, 데이터를 깔끔하게 정리하여 더 일관된 분석 결과를 얻기 위해 필요하다.
•
Tokenization: 토크나이징은 텍스트를 개별 단어나 구(phrase)와 같은 더 작은 단위로 분할하는 과정이다. 이 과정은 텍스트 데이터를 분석할 때 필수적이며, 텍스트 내에서 단어의 빈도를 계산하거나 문장 구조를 이해하는 데 도움이 된다. 토크나이징을 통해 텍스트가 구조화되어, 다양한 분석 기법을 적용하기 용이해진다.
•
Filtering: 필터링은 특정 기준에 따라 텍스트에서 단어나 표현을 제외하는 과정이다. 예를 들어, 흔히 쓰이지만, 분석에는 큰 의미가 없는 불용어(stopwords)를 제거하거나, 특정 품사(예: 명사나 동사)만을 선택하여 분석에 포함시키는 것이 여기에 해당된다. 필터링은 분석의 중요성이 낮은 정보를 제거함으로써, 보다 중요한 데이터에 집중할 수 있게 해 준다.
3. Word Cloud
[Preprocess Text]에 [Word Cloud]를 연결한다.
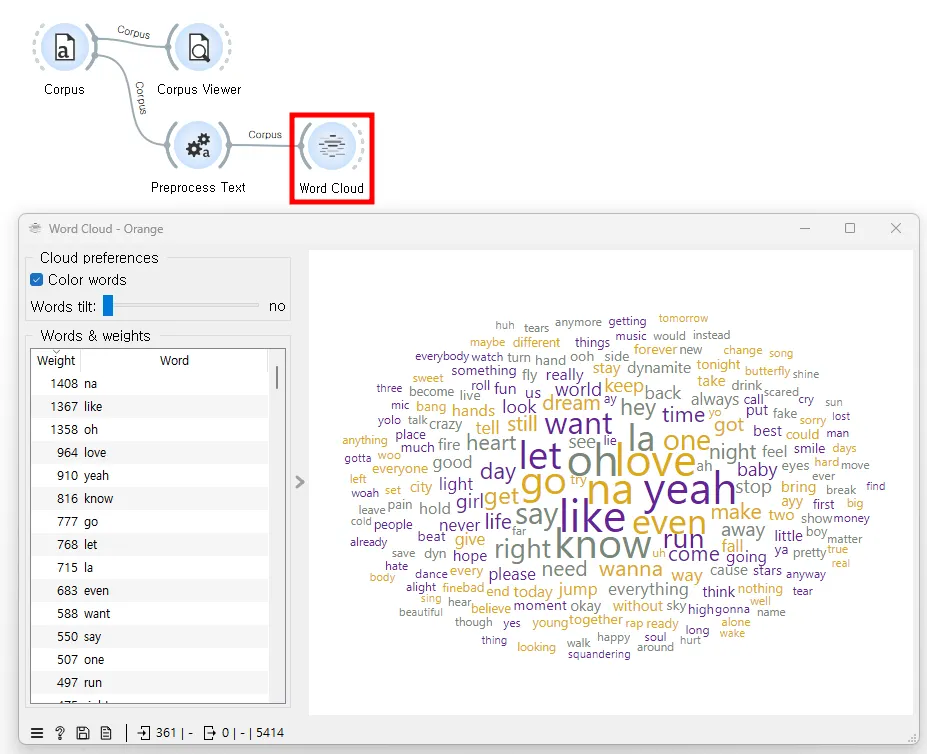
[Word Cloud]에서 'weight'는 각 단어의 중요도 또는 빈도를 나타낸다. 일반적으로 단어의 무게(Weight)가 클수록 그 단어는 텍스트 내에서 더 자주 등장하며, 따라서 워드 클라우드에서 더 크게 표시된다. 이는 해당 단어가 전체 텍스트 내에서 차지하는 비중이나 중요성을 시각적으로 표현한 것으로, 보는 이로 하여금 한눈에 어떤 주제나 키워드가 중요한지 파악할 수 있게 한다. 워드 클라우드를 통해 가장 관련성 높거나 언급이 많이 된 단어들을 쉽게 식별할 수 있다.
아래 워드 클라우드에서 ‘na’, ‘like’, ‘oh’, ‘love’, ‘yeah’와 같이 크게 표시된 단어들은 그 단어들이 가사 데이터셋에서 가장 자주 등장하는 단어임을 나타낸다. ‘na’가 1,408회, ‘like’가 1,367회 등장하는 것처럼 각 단어의 빈도는 워드 클라우드의 왼쪽 패널에 'Weight'으로 표시되어 있다.
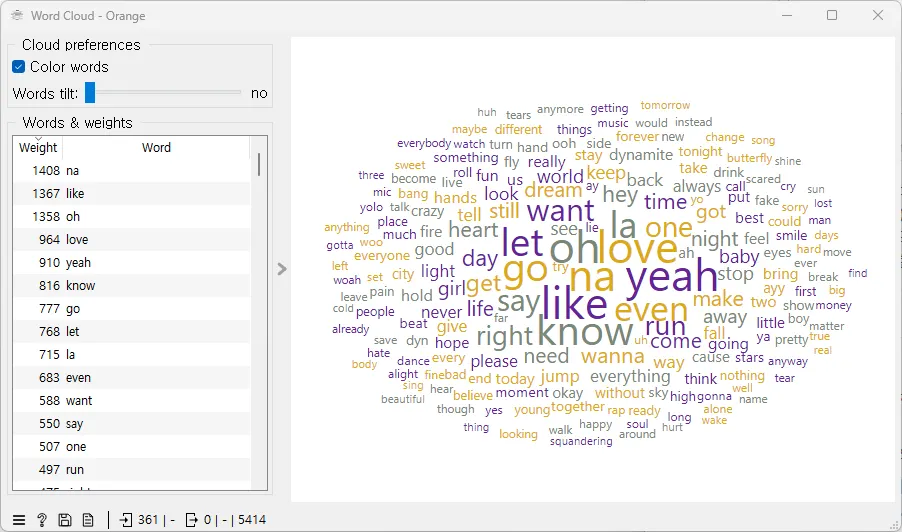
워드 클라우드의 디자인은 다양한 색상을 사용하여 가독성을 높이고 시각적으로 흥미로운 효과를 준다. 특히, ‘love’와 같이 감정과 관련된 단어들이 포함된 것은 BTS의 가사가 긍정적이거나 감정적인 주제를 자주 다룬다는 점을 시사한다. 더 나은 워드 클라우드를 만들기 위하여 추가로 [Preprocess Text] 위젯의 불용어 필터링 설정을 조정하는 것을 생각해 볼 수 있다. ‘get’, ‘like’, ‘go’와 같은 일반적으로 많이 사용되는 단어들은 분석에 깊이를 더하지 않기 때문에 이를 추가적으로 필터링하는 것이다. [Preprocess Text] 위젯에서 이러한 불용어를 제거함으로써, 데이터의 중요한 요소들이 더욱 돋보이게 하고, 분석 결과의 품질을 향상 시킬 수 있다.
4. Sentiment Analysis
앞서 작업한 [Preprocess Text] 위젯에 [Sentiment Analysis] 를 연결한다.
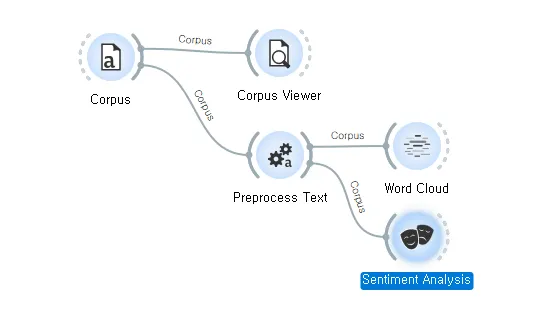
[Sentiment Analysis] 위젯은 텍스트로부터 감정을 예측하는 기능을 제공한다. 이 위젯은 여러 가지 감정 분석 모듈을 사용하여 각 문서의 감정을 분석하고 결과를 코퍼스에 추가한다. 사용 가능한 모듈에는 Liu & Hu, Vader, 다양한 언어를 지원하는 다국어 감정 사전, SentiArt, LiLaH 등이 포함되어 있다. 이러한 감정 분석 도구를 통해 문서에 대한 긍정적, 부정적, 중립적 점수를 계산하고, 이러한 점수를 데이터 분석과 시각화에 활용할 수 있다.
<Sentiment Analysis 항목별 설명>
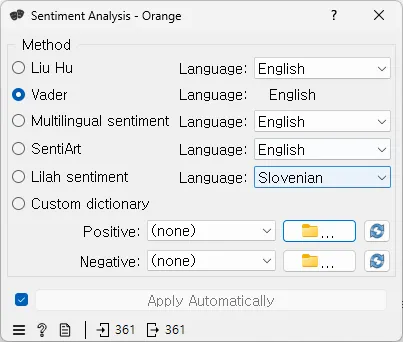
•
Liu Hu: 사전 기반 감정 분석으로, 영어와 슬로베니아어를 지원한다. 긍정적 및 부정적 단어의 합에서 차이를 계산하고 문서의 길이로 정규화하여 100을 곱한 최종 점수를 제공한다. 이 점수는 문서 내 감정 차이의 백분율을 나타낸다.
•
Vader: 사전 및 규칙 기반 감정 분석이다.
•
다국어 감정: 여러 언어를 지원하는 사전 기반 감정 분석이다.
•
SentiArt: 벡터 공간 모델을 기반으로 한 감정 분석으로, 텍스트의 정서적 가치를 반환한다.
•
LiLaH 감정: NRC 감정 어휘 사전의 수동 번역을 사용한다.
•
사용자 정의 사전: 자신의 긍정 및 부정 감정 사전을 추가할 수 있다. 파일 형식은 .txt이며, 각 단어는 별도의 줄에 있어야 한다. 최종 점수는 Liu Hu와 같은 방식으로 계산된다.
[Sentiment Analysis]를 ‘SentiArt’로 설정하고, [Data Table]을 연결하여 감정을 분석한 결과를 살펴보자.
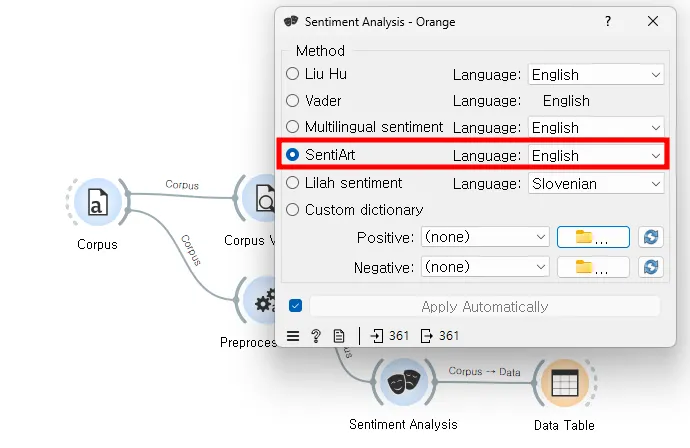
SentiArt는 텍스트의 감정적 가치를 평가하여 가사가 전달하는 감정의 뉘앙스를 이해하는 데 도움을 준다. 이것을 통해 BTS 가사에서 전달하고자 하는 메시지를 분석할 수 있다.
BTS 가사를 감정 분석한 결과는 각 가사에 대한 다양한 감정 점수들을 보여준다. 이러한 점수는 분석 대상인 텍스트 내에 해당 감정이 얼마나 존재하는지를 나타낸다.
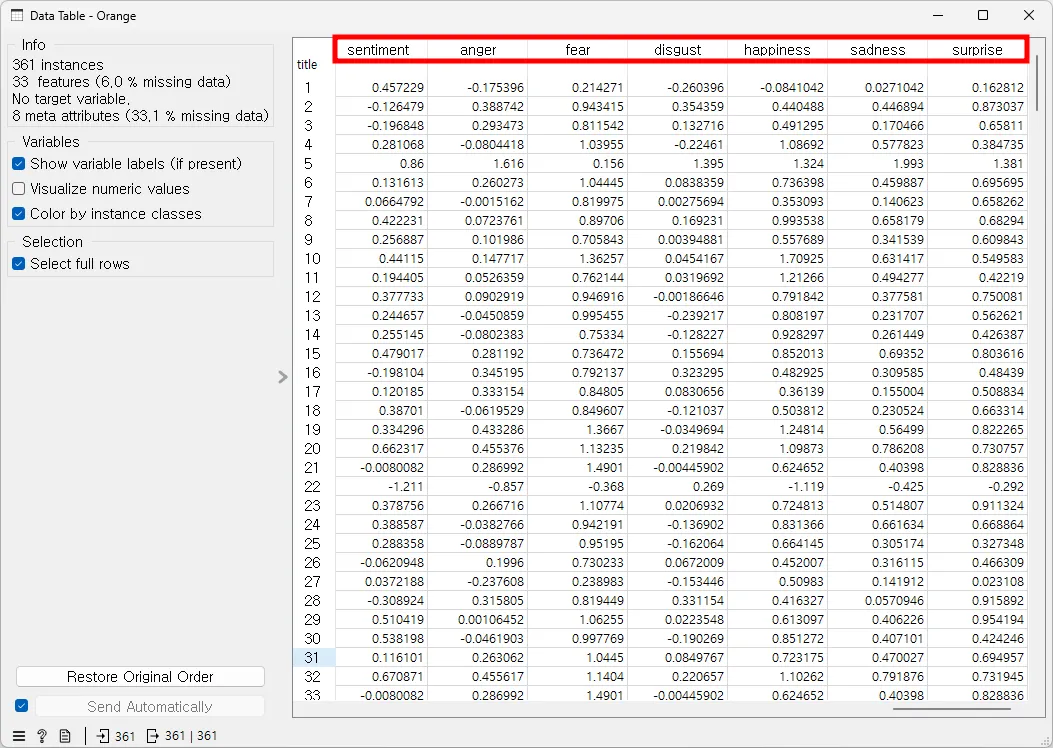
•
sentiment: 긍정적인 감정 점수는 긍정적인 분위기를 나타낸다.
•
anger, fear, disgust: 분노, 두려움, 혐오 점수는 부정적인 감정과 관련이 있다.
•
happiness: 높은 행복 점수는 긍정적인 감정을 가리킨다.
•
sadness: 슬픔은 더 어두운 또는 부정적인 분위기를 나타낸다.
•
surprise: 놀람은 문맥에 따라 긍정적이거나 부정적일 수 있다.
예를 들어, 높은 긍정적 감정 점수와 행복 점수를 가진 곡은 매우 긍정적이고 즐거운 메시지를 전달
하고 있다고 볼 수 있다. 반대로 슬픔이나 분노 점수가 높은 곡은 투쟁이나 좌절의 주제를 반영할 수
있다. 각 점수는 가사의 내용과 아티스트가 전달하고자 하는 전체 메시지의 맥락에서 해석되어야 한
다.
[Data Table]에 [Scatter Plot]을 연결하고, 아래 이미지처럼 설정하면 각각의 곡이 어떤 감정을 표현하고 있는지 쉽게 살펴볼 수 있다.
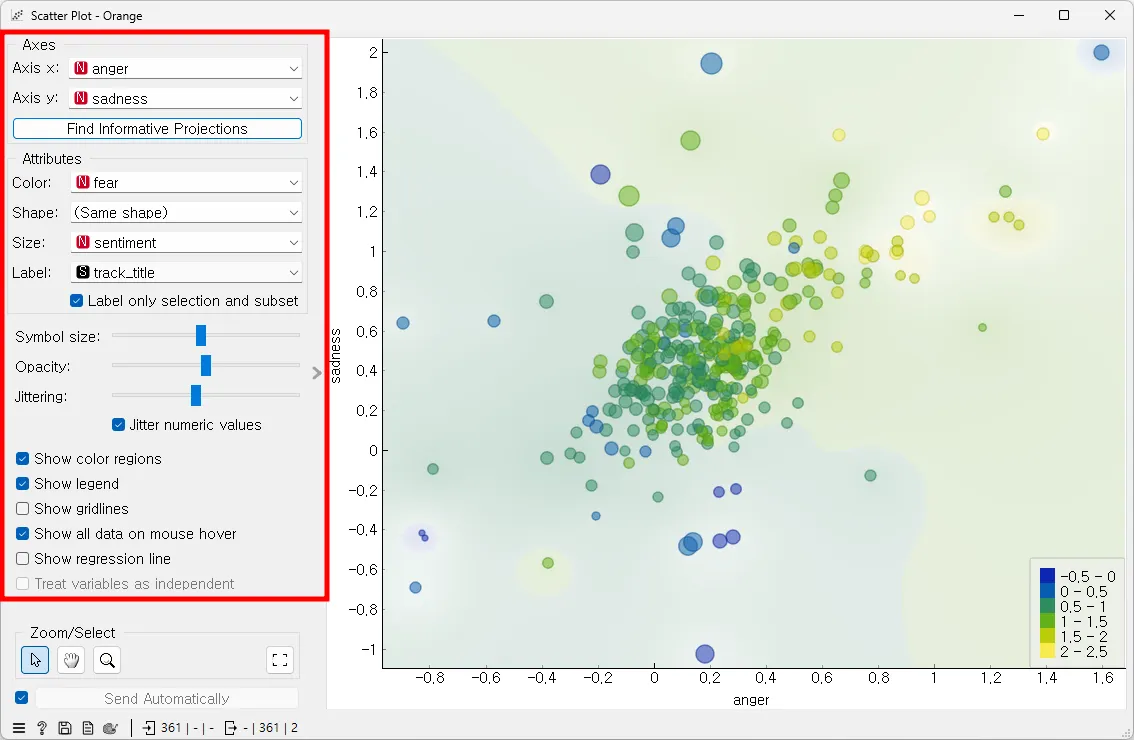
[Scatter Plot] 위젯은 데이터를 산점도로 시각화해 준다. 이 산점도는 데이터 포인트를
X축과 Y축에 점으로 표시하여 두 변수 간의 관계를 시각적으로 표현한다. 여기서 X축은 'anger'(분노), Y축은 'sadness'(슬픔) 속성으로 설정되어 있어, 각 데이터 포인트의 분노와 슬픔의 정도를 비교 분석할 수 있다. 또한, 색상은 'fear'(공포) 속성에 따라 다르게 표시되고, 크기는 'sentiment'(감정의 강도) 속성에 따라 조절된다. 이를 통해 각각의 데이터 포인트가 표현하는 감정의 강도와 공포의 정도를 한눈에 파악할 수 있다. 각 데이터 포인트는 'track_title'(트랙 제목)로 라벨링 되어 있어, 어떤 트랙이 어떤 감정을 표현하고 있는지 식별할 수 있다.
[Data Table]에 [Bar Plot]을 연결하고, 아래와 같이 설정하면, 각 곡이 표현하는 감정의 정도를 막대 그래프를 통해 직관적으로 파악하여, 각 트랙별로 어떤 감정이 강하게 나타나는지 시각적으로 쉽게 비교할 수 있다.
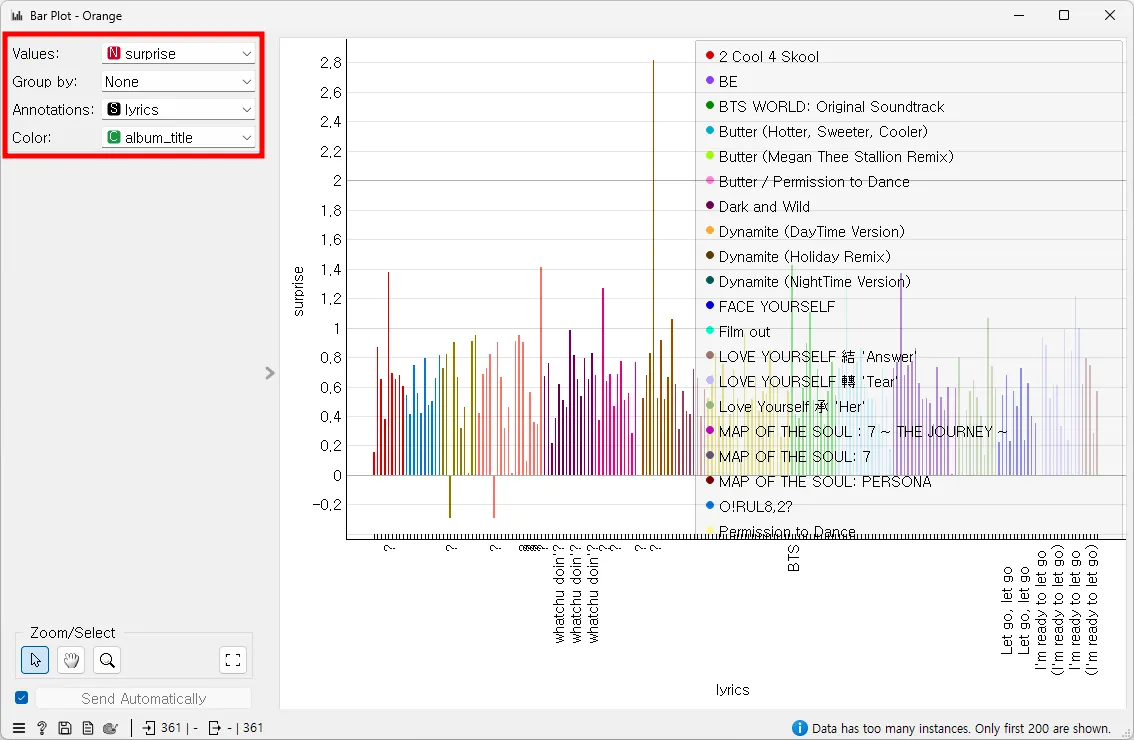
[Bar Plot] 위젯은 데이터를 막대그래프로 시각화해 준다. 이 그래프는 각 데이터 포인트에서의 놀라움의 정도를 'surprise' 속성을 기반으로 막대의 높이로 표현함으로써 특정 변수에 대한 분포를 시각화하고 있다. 막대의 색상은 'album_title' 속성에 따라 달라져, 각 앨범에서 놀라움의 정도를 쉽게 구분할 수 있게 해준다.
또한, 'lyrics' 속성이 주석으로 사용되어 각 막대에 표시되며, 이는 해당 데이터 포인트의 가사 일부를 나타내어 어떤 가사 부분에서 놀라움의 정도가 높았는지 연결 지어 생각할 수 있게 해 준다. (그래프 하단의 메시지는 데이터 포인트의 수가 많아 그래프에 모두 표시되지 않았음을 의미함)이 막대그래프는 앨범별로 놀라움의 정도가 어떻게 다른지 비교 분석하는 데 유용하며, 특정 가사에서 놀라움을 많이 나타내는 곡을 식별하는 데 도움을 준다.
마지막으로 [Data Table]에 [Distributions]을 연결하고 Filter를 ‘happiness’로 설정하면, happiness의 대한 히스토그램을 확인할 수 있다.
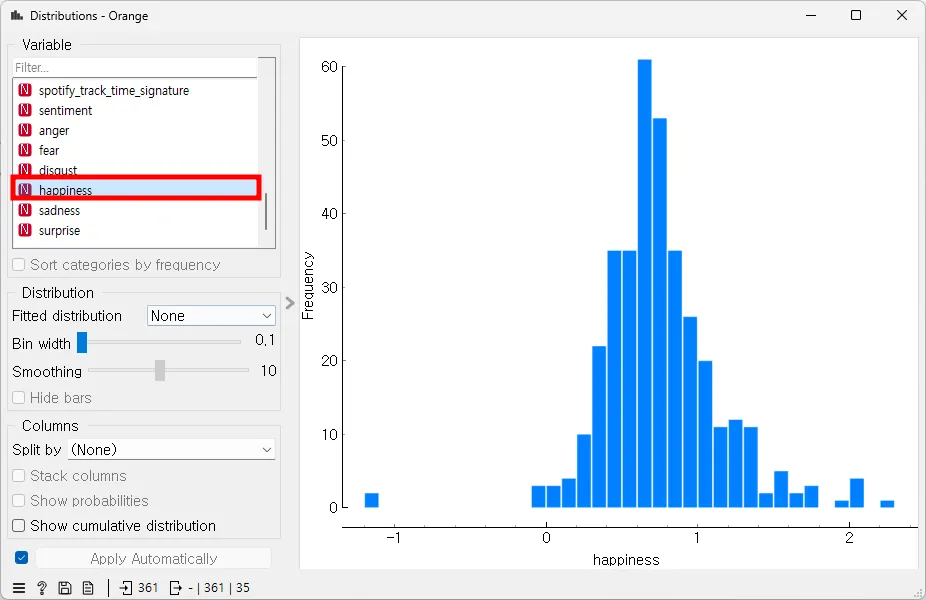
[Distrubutions] 위젯은 데이터를 히스토그램으로 시각화해 준다. 해당 히스토그램은 'happiness' 변수의 데이터 분포를 나타내며, 데이터 포인트(BTS 곡)들의 행복의 정도를 시각적으로 분석할 수 있게 해준다. X축은 'happiness' 값이며, Y축은 해당 값들이 나타나는 빈도수이다. 각 막대는 'happiness' 값의 특정 범위에 해당하는 데이터 포인트들의 수를 나타낸다. 분석 결과, 대부분의 'happiness' 값은 0.3에서 0.9 사이에 집중되어 있음을 확인할 수 있다. 특히, 0.6에서 0.9 사이의 구간에 가장 많은 데이터 포인트가 위치해 있으며, 이는 데이터셋 내에서 해당 범위의 행복감이 가장 일반적임을 보여준다. 또한, 매우 높은 'happiness' 값(예: 2.0 이상)과 매우 낮은 값(예: -0.6 이하)은 상대적으로 드물게 나타나는데, 이는 비교적 드문 사례이거나 특이한 데이터 포인트일 가능성이 있다.
지금까지 Orange3의 Text Mining 탭의 다양한 위젯을 사용하여 BTS 가사 데이터셋을 분석해 보았다.
분석한 결과, 'happiness'의 값이 주로 0.3에서 0.9 사이에 집중되어 있음을 확인할 수 있다. 이는 BTS
의 가사가 주로 긍정적인 감정을 표현하고 있음을 시사한다. [Distributions] 위젯으로 생성된 히스토
그램은 이러한 분석 결과를 직관적으로 보여주며, 막대그래프와 산점도를 통해 각 곡의 감정적 특성
을 더욱 명확히 파악할 수 있었다. 이러한 도구들은 데이터에서 중요한 패턴과 특성을 식별하고, 감정
분석을 통해 가사가 전달하고자 하는 감정의 뉘앙스를 이해하는 데 큰 도움을 준다.
이 데이터 분석 활동은 학생들에게 텍스트 마이닝의 실제 적용 사례를 제공하여, 데이터 과학과 감정
분석의 기본 원리를 이해하고 실습할 수 있는 좋은 기회가 될 것이다.