

안녕하세요, 시리얼쌤입니다.  오늘은 매달 발간되는 [공공데이터를 활용한 데이터 과학] 시리즈물로 인사드립니다!
오늘은 매달 발간되는 [공공데이터를 활용한 데이터 과학] 시리즈물로 인사드립니다!
오늘은 매달 발간되는 [공공데이터를 활용한 데이터 과학] 시리즈물로 인사드립니다! 최근에는 오렌지, 엔트리, 파이썬 등 다양한 도구를 활용한 데이터 분석 및 인공지능 융합 활동이 많아지고 있는 것 같습니다.
그러나 여전히 타이타닉 생존자 예측, 붓꽃이나 펭귄 품종 분류, 보스턴 집값 예측처럼 학생들의 삶과는 다소 거리가 있는 예제를 활용하는 경우가 많습니다…
이러한 한계를 극복하기 위해서 학생들이 실제 삶과 연결된 주제를 직접 탐구할 수 있도록 수업 계획 시 데이터 선택에 심혈을 기울이는 편인데요, 그런 점에서 SDGs(지속가능발전목표)는 현실적인 문제의식과 탐구 주제를 동시에 제공해 줄 수 있어 추천해 드립니다!
이러한 한계를 극복하기 위해서 학생들이 실제 삶과 연결된 주제를 직접 탐구할 수 있도록 수업 계획 시 데이터 선택에 심혈을 기울이는 편인데요, 그런 점에서 SDGs(지속가능발전목표)는 현실적인 문제의식과 탐구 주제를 동시에 제공해 줄 수 있어 추천해 드립니다!
우선 지속가능개발목표(SDGs)란, 국제기구에서 발표한 2030년까지 모든 나라들이 더 나은 세상을 위해 함께 달성해야 할 총 17개의 목표와 169개의 세부 목표를 의미합니다.

(다양한 주제와 데이터 관련 수업 소재로 삼으면 좋을 만한 소스들이 많아, 타 교과에서도 많이들 융합 수업에 활용하는 것 같습니다. 최근에 공식적으로 ‘지표누리’ 사이트에서 지속가능발전목표 연계 데이터를 제공해 주기도 한답니다. →  지속가능발전목표(SDG))
지속가능발전목표(SDG))

그중에서도 저는 오늘 ‘12. 책임 있는 소비와 생산’을 주제로 데이터 분석을 진행한 사례를 말씀드리겠습니다!
많이 부족한 부분이 많지만, 저의 사례를 보고 선생님들께서 더 보완하셔서 멋진 프로젝트를 완성하시면 좋겠습니다. ㅎㅎ
0. 출발
음식물쓰레기 감량을 위해 우리나라는 2013년부터 본격적으로 RFID 종량제를 실행하고 있습니다.
아마 우리가 모두 이미 경험한 적이 있을 텐데요, 장비에 카드를 인식한 후 배출하면 배출자와 음식물 쓰레기 무게 정보가 환경부 중앙시스템으로 전송되어 수수료를 관리할 수 있도록 하는 방식을 말합니다.
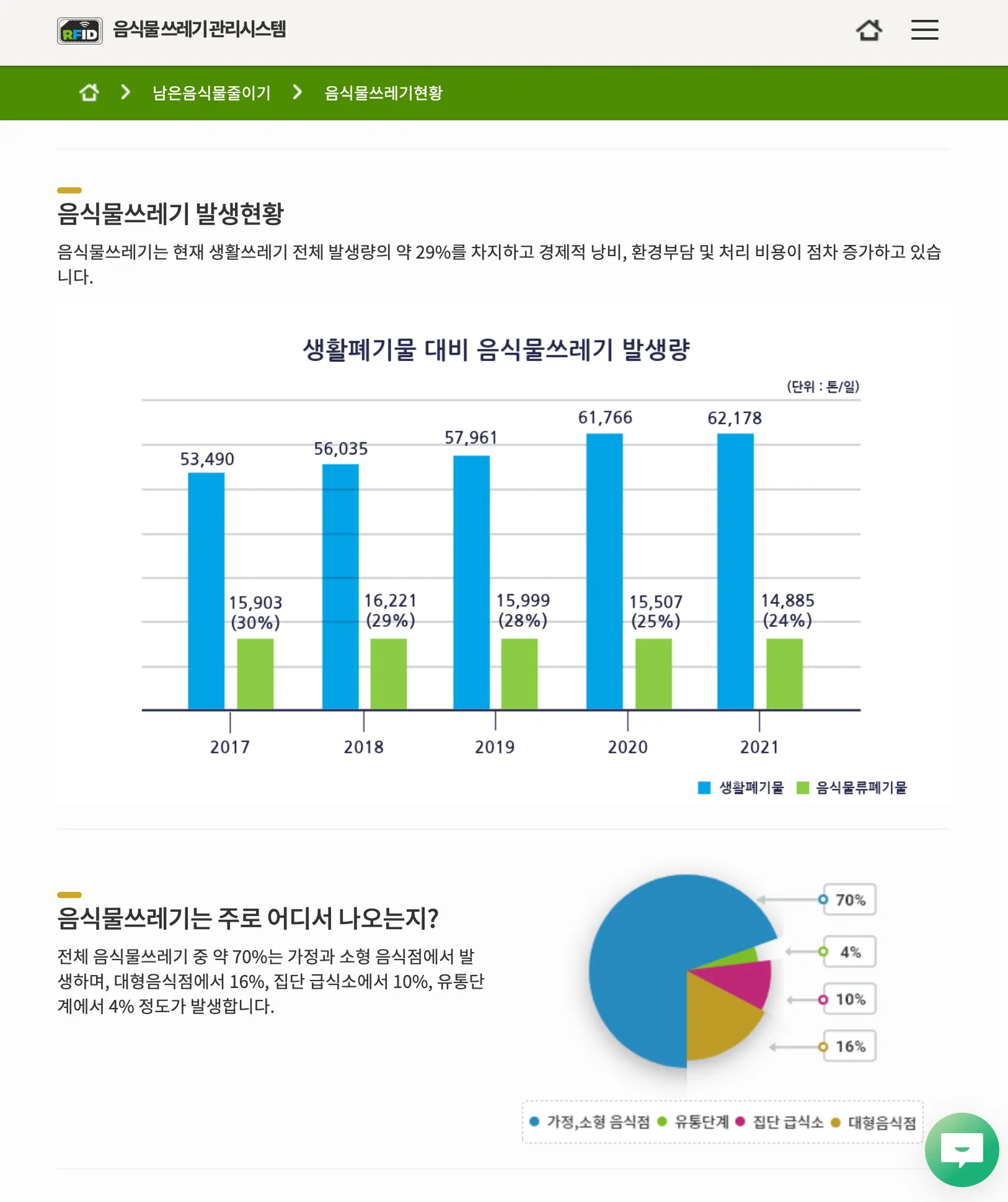

( 이미지 출처 :  뉴스젤리 : 데이터 시각화 전문 기업 ← 실제로 저도 뉴스레터를 구독 중이고,
가끔 괜찮은 시각화 자료들을 보고 수업 전에 학생들과 함께 이야기를 나눠보기도 합니다.)
뉴스젤리 : 데이터 시각화 전문 기업 ← 실제로 저도 뉴스레터를 구독 중이고,
가끔 괜찮은 시각화 자료들을 보고 수업 전에 학생들과 함께 이야기를 나눠보기도 합니다.)
저는 MBTI N 성향답게 평범한 일상에서도 여러 가지 생각들이 꼬리에 꼬리를 물며 이어지곤 합니다.
얼마 전 단지 내 음식물 쓰레기를 버리면서,
’예전에 비해 종량제 봉투를 사용하지 않으니까 비닐 사용량도 줄어들었겠지?
→ 그럼, 사료나 퇴비를 만들 때 효율이 더 올라가려나?
→ 주말에 배달 음식을 더 많이 시켜 먹는다면 주말 배출량이 주중보다 많을까?
→ 대부분의 음식물 쓰레기는 일반 가정보다는 대형/소형 음식점에서 많이 발생할 텐데,
해당 구역에는 이런 장비가 더 많이 설치되어 있을까?
→ 실제로 RFID 종량제를 도입한 후 배출자들의 부담으로 인해 음식물쓰레기가 감량되는 효과가 있었을까?’
등등… 여러 가지 생각이 들면서
’실제 환경부 데이터를 활용해서 궁금증을 해소해보자!’ 라는 결론에 이르게 되었습니다. ㅎㅎ
1. 데이터 수집
공공데이터 포털( 한국환경공단_지자체별(일별) RFID음식물쓰레기 배출량_20240131)의 데이터를 수집하여, 제가 살고 있는 경기도 기준 3년치 음식물 쓰레기 배출량 데이터를 취합하였습니다.
한국환경공단_지자체별(일별) RFID음식물쓰레기 배출량_20240131)의 데이터를 수집하여, 제가 살고 있는 경기도 기준 3년치 음식물 쓰레기 배출량 데이터를 취합하였습니다.
한국환경공단_지자체별(일별) RFID음식물쓰레기 배출량_20240131)의 데이터를 수집하여, 제가 살고 있는 경기도 기준 3년치 음식물 쓰레기 배출량 데이터를 취합하였습니다.
저는 일주일 중 가장 음식물 쓰레기 배출량이 많은 요일도 궁금해서,

‘배출요일’이라는 열을 하나 추가하였습니다!
배출요일 열 생성 함수
2. 데이터 분석
코랩에서 데이터 분석을 진행해 보겠습니다.
2-1. 시각화를 위한 사전작업
•
한글 표시를 위해 아래 코드 실행 후
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
(아래는 완성본 파일입니다. 🔽)
Python
복사
꼭! 세션을 다시 시작해주세요.
전체 코드는 마지막 부분에 첨부해 둔 완성본 파일을 참고해 주시고,
몇 가지 데이터 분석을 위해 필요한 작업만 일부 설명드리겠습니다.
2-2. 데이터 불러오기
•
판다스 라이브러리를 추가해 주시고,
•
활용한 데이터의 경로를 복사해서 불러옵니다.
#pandas 라이브러리 추가
import pandas as pd
#데이터 불러오기
df = pd.read_csv('/content/gyeonggi_foodwaste.csv', encoding='cp949')
df
'''
#참고 : 코랩에서 드라이브 마운트 후 경로 확인하기
from google.colab import drive
drive.mount('/content/drive')
#파일 이름 일치 여부 확인
!ls "/content/drive/MyDrive/Colab Notebooks"
'''
Python
복사
•
배출연도, 배출월, 배출일, 배출요일은 카테고리 데이터타입으로 변경해 줍니다.
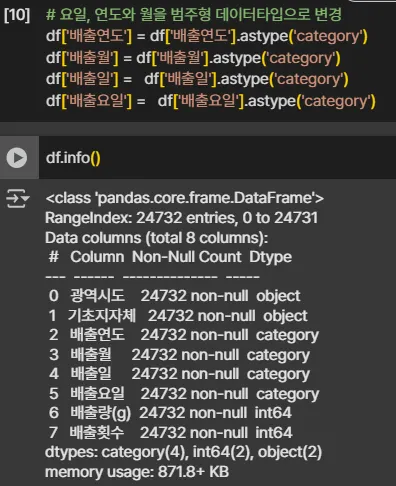
2-3. 데이터 통계 정보 한눈에 확인하기
•
df.describe() : 수치형 자료의 기초 통계량(갯수, 평균, 표준편차, 최대, 최소 …)
•
df.describe(include='O') : 범주형 object 자료의 기초 통계량
•
df.describe(include='category') : 범주형 category 자료의 기초 통계량
2-4. 그룹화
#연도별 요일별 배출량, 배출횟수 평균
dfg = df.groupby(['배출연도', '배출요일'])[['배출량(g)', '배출횟수']].mean().round(2)
dfg
#인덱스 재설정
dfg = dfg.reset_index()
dfg
Python
복사
데이터를 그룹별로 분류하여 인덱스를 재설정해 보겠습니다.
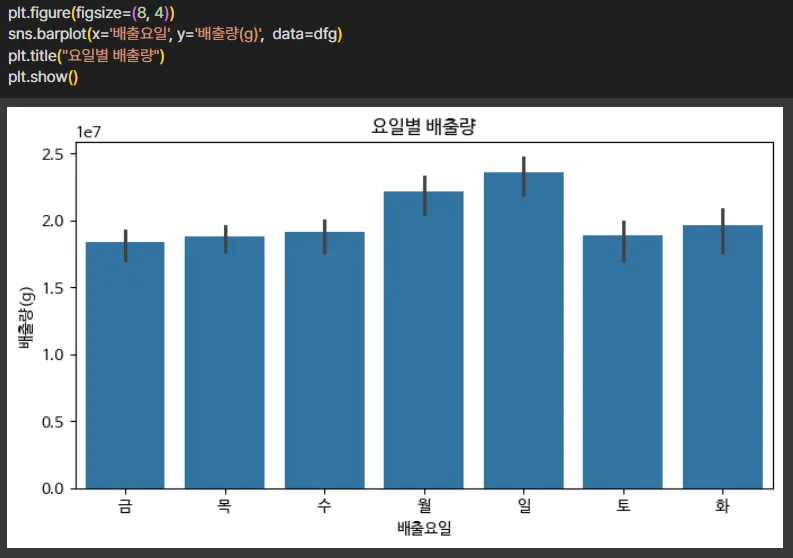
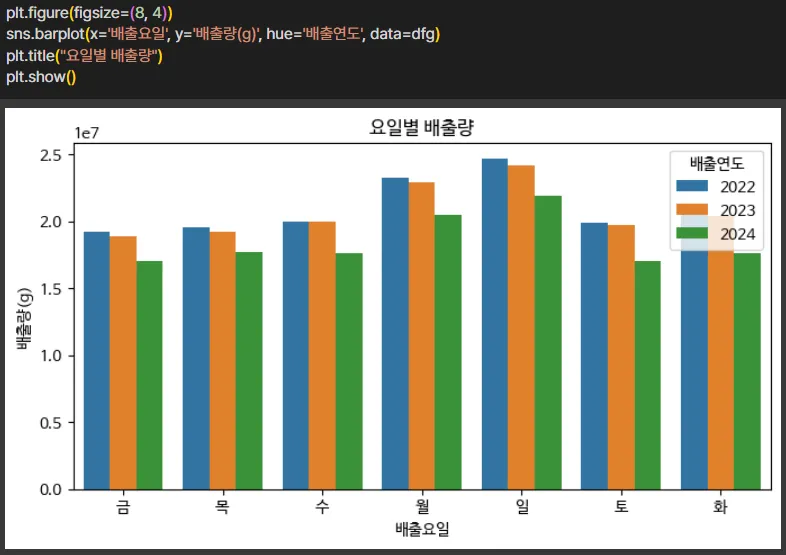
처리된 데이터를 기반으로 살펴보면,
일요일이 음식물쓰레기 배출량이 가장 많았으며
hue= ‘배출연도’를 설정해 주시면 연도별, 요일별 배출량을 비교해 볼 수 있습니다.
2-4. 데이터 프레임 합치기
•
pd.concat() 으로 데이터프레임을 이어 붙여주겠습니다.
pd.concat([연결할 데이터프레임명리스트],axis=1, join='inner')
#axis : 연결 방향 (0-행, 1-열)
#join : 방식 (outer : 합집합, inner :교집합
#2023, 2024년 자료 분리
dfg2023 = dfg[dfg['배출연도'] == 2023]
dfg2024 = dfg[dfg['배출연도'] == 2024]
#2023, 2024년 요일을 인덱스로 설정
dfg2023 = dfg2023.set_index('배출요일')
dfg2024 = dfg2024.set_index('배출요일')
#2023, 2024년 배출량비율 배출횟수비율
dfgw = pd.concat([dfg2023, dfg2024], axis=1)
dfgw
#필요한 열만 골라내줍니다.
dfgw = dfgw.iloc[: , [1, 2, 4, 5]]
dfgw
Python
복사
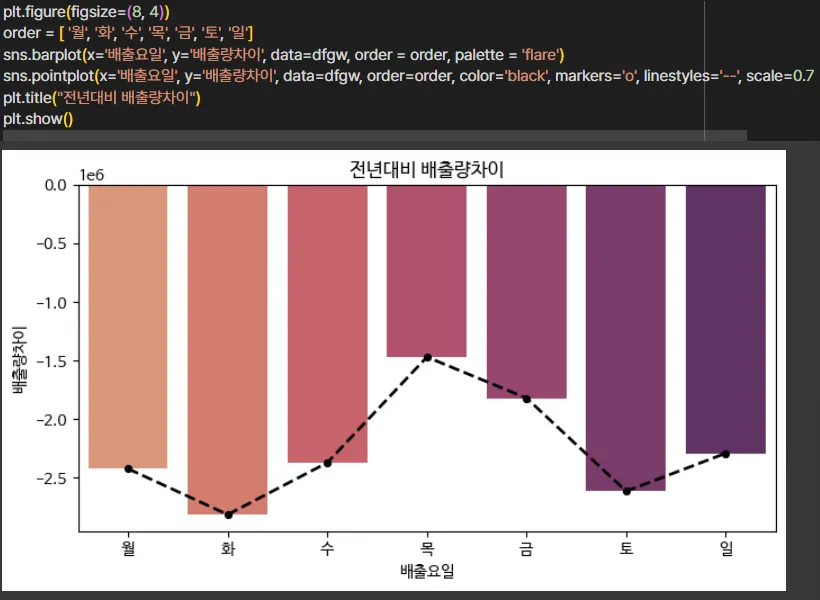
발굴할 수 있는 인사이트 (Thanks to GPT)
실제로 음식물 쓰레기 배출량이 점점 줄어들고 있다는 것뿐만 아니라,
더 정교하게 지속 가능한 생활 실천의 확산 가능성도 확인해 볼 수 있었습니다.
완성본 파일
3. 확장 및 응용 (?)
분량 관계상 저의 러프한 아이디어만 제안드리고 마무리하려 합니다.
3-1. 선형회귀 분석으로 미래의 음식물쓰레기 배출량 예측해 보기
3-2. Streamlit을 활용하여 워드클라우드, 지도 등 시각화를 더 다양화하여 웹앱 형태로 구현 후 공유
3-3. 실제 가장 음식물쓰레기 배출량이 많은 지역과 음식물종량기기 설치 현황 비교

추가 데이터를 기반으로 새로운 기기 설치 위치 제안 등
SDGs 기반 공공데이터 속에서 삶을 읽고, 질문을 발견하며
더욱 다양한 방식으로, 데이터로 읽고, 듣고, 말할 수 있을 것 같습니다!
정보과 선생님들의 더 깊고 넓은 데이터 리터러시 수업에 작은 보탬이 되었길 바랍니다 :)
수업 속 데이터가 학생들이 세상을 읽는 힘으로 이어지길 바라며!