
단계 1: 데이터 불러오기
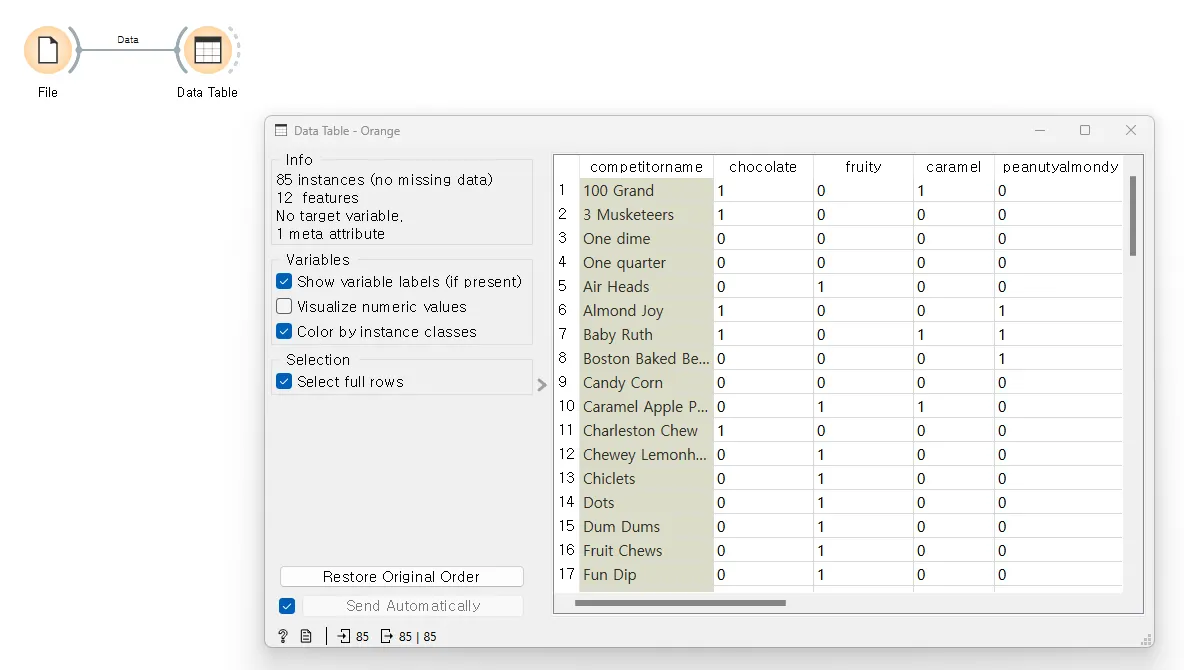
데이터셋: 캐글의 'The Ultimate Halloween Candy Power Ranking' 데이터셋은 가장 인기 있는 할로윈 사탕을 파악하기 위해 수집된 데이터입니다. 참가자들이 두 가지 재미있는 사이즈 캔디 중에서 받고 싶은 것을 선택하도록 하는 웹사이트를 통해 데이터를 수집했으며, 총 8,371개의 다른 IP 주소에서 26만 9천 표 이상이 모였습니다.
 ‘File' 위젯을 열고, 다운로드한 할로윈 사탕 데이터셋을 불러옵니다. 데이터가 정상적으로 불러와졌는지 'Data Table'을 통해 확인합니다.
‘File' 위젯을 열고, 다운로드한 할로윈 사탕 데이터셋을 불러옵니다. 데이터가 정상적으로 불러와졌는지 'Data Table'을 통해 확인합니다.
단계 2: 사탕 선호도 순위 매기기
'Rank' 위젯을 데이터셋에 연결하여 사탕별 선호도 순위를 확인합니다. 가장 인기 있는 사탕을 찾아보세요. 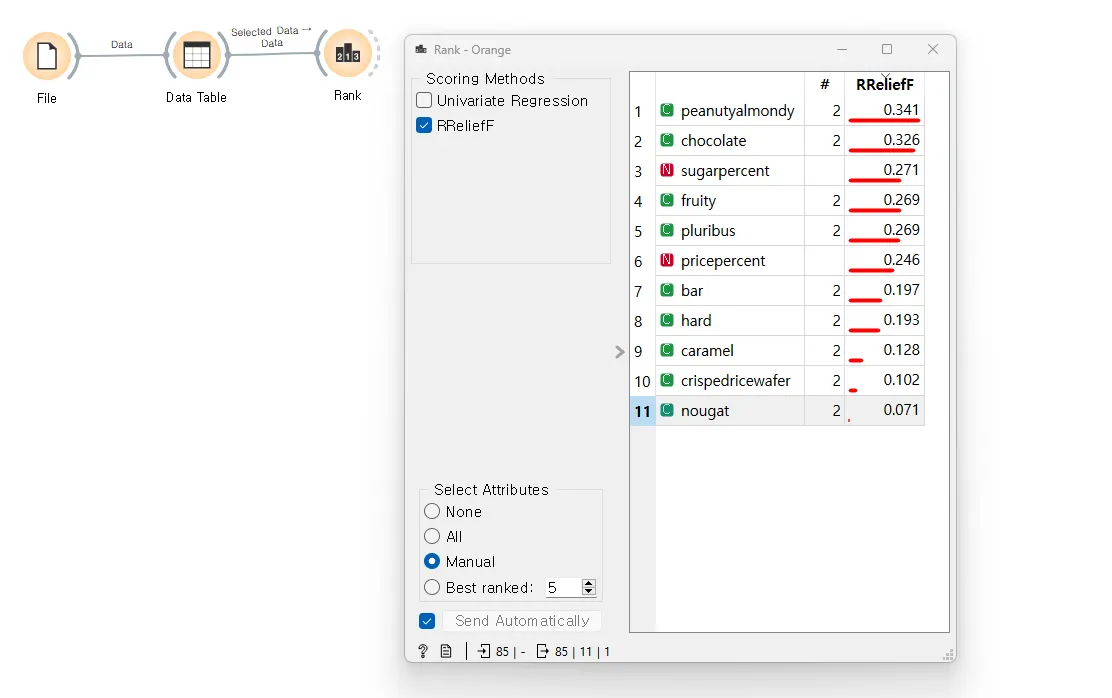
RReliefF 알고리즘은 데이터셋의 타겟 변수를 예측하는 데 각 특성(Feature)의 중요도를 평가하는 방법으로 사용됩니다. 이 알고리즘은 각 특성에 RReliefF 가중치를 할당하여, 해당 특성이 타겟(Target, 그림3 에선 승률(winpercent)) 변수 예측에 기여하는 정도를 수치적으로 나타냅니다.
•
peanutyalmondy: 0.341의 가중치를 가지며, 이 데이터셋에서 가장 중요한 특성으로 평가되었습니다.
•
chocolate: 0.326의 가중치로 두 번째로 중요한 특성입니다.
•
sugarpercent: 0.271의 가중치를 가지며, 세 번째로 중요한 특성으로 나타납니다.
•
fruity, pricepercent, bar, hard, caramel, crispedricewafer, nougat는 그 다음으로 중요한 특성들을 나타냅니다.
이러한 가중치를 통해, 예측 모델을 만들 때 어떤 특성들이 가장 유의미한 영향을 미칠 수 있는지에 대한 통찰을 얻을 수 있습니다. 예를 들어, 'peanutyalmondy'와 'chocolate' 같은 특성들은 캔디를 선호하는 데 있어서 중요한 역할을 할 수 있으며, 모델 학습에 있어서 우선적으로 고려될 수 있습니다.
단계 3: 데이터 시각화 및 탐색하기
1.
변수 간 상호작용 살펴보기:
•
‘Mosaic Display’ 위젯을 사용합니다.
•
(예) ‘chocolate’과 ‘fruity’와 같은 이진 변수들의 조합과 승률 사이의 관계를 시각화합니다.
2.
이진 변수의 분포 살펴보기:
•
‘Bar Chart’ 위젯을 사용하여 각 이진 변수에 대한 카운트를 시각화합니다.

이 그래프는 'fruity'와 'chocolate'의 모든 조합에서 승률을 비교하고 있습니다.
•
초콜릿이 없고 과일 맛이 없는 사탕은 파란색과 빨간색 영역으로 표시되어 있어, 이들의 승률이 가장 낮다는 것을 의미합니다.
•
초콜릿이 있지만 과일 맛은 없는 사탕은 주황색과 밝은 녹색으로 표시되어 있어, 이들의 승률이 더 높음을 보여줍니다.
•
초콜릿이 없지만 과일 맛이 있는 사탕은 주로 주황색으로 표시되어 있어, 중간 정도의 승률을 나타냅니다.
•
초콜릿과 과일 맛이 모두 있는 사탕은 주로 빨간색으로 표시되어 있어, 낮은 승률을 가지고 있음을 암시합니다.

이 바 차트는, 할로윈 사탕의 승률을 'chocolate' 성분이 포함되었는지 여부에 따라 그룹화하여 나타낸 것입니다. 바 차트의 x축에는 'chocolate'의 포함 여부에 따른 두 그룹이 있습니다, 0은 초콜릿이 포함되지 않은 사탕을, 1은 초콜릿이 포함된 사탕을 나타냅니다. y축은 'winpercent' 값으로, 각 사탕의 승률을 수치로 표현합니다.
차트의 파란색 바는 초콜릿이 포함되지 않은 사탕을, 빨간색 바는 초콜릿이 포함된 사탕을 나타냅니다. 각 바의 높이는 해당 사탕의 평균 승률을 나타내며, 이를 통해 초콜릿의 유무가 사탕의 인기에 어떤 영향을 미치는지 비교할 수 있습니다. 눈에 띄는 것은 초콜릿이 포함된 사탕들이 평균적으로 더 높은 승률을 가지고 있는 것으로 보입니다. 이 데이터 시각화는 사탕의 인기 요소 중 하나로 초콜릿 성분의 중요성을 강조하고 있습니다.
단계 4: 결정 트리를 사용해 분류하기
1.
데이터 준비:
•
‘Data Sampler’ 위젯으로 훈련 데이터와 테스트 데이터를 나눕니다.
2.
결정 트리 학습:
•
‘Tree’ 위젯을 사용하여 이진 변수를 기반으로 결정 트리를 만들고, 사탕의 승률을 예측합니다.
3.
트리 결과 해석:
•
생성된 트리를 ‘Tree Viewer’ 위젯으로 시각화하고, 어떤 변수가 승률 예측에 가장 중요한 영향을 미치는지 논의합니다.

노드에 표시된 숫자는 각 조건을 만족하는 캔디의 평균 승률과 그 표준 편차를 나타냅니다. 예를 들어, 'sugarpercent'가 0.313을 초과하고 'caramel' 성분이 있는 캔디는 평균 승률이 34.0%이며 그 표준 편차는 0.3이라고 할 수 있습니다.
‘2 instances’는 그 조건을 만족하는 캔디가 두 개 있다는 의미입니다. 이 의사 결정 트리는 캔디의 특성과 승률 사이의 관계를 파악하는 데 도움을 주며, 어떤 특성이 승률에 가장 큰 영향을 끼치는지 분석할 수 있게 해줍니다. 트리는 승률을 높이는 방향으로 데이터를 우선적으로 분할하며, 각 분기점은 승률을 최대화하는 조건을 나타냅니다.
이 프로젝트는 학생들에게 데이터 과학의 기본을 가르치면서 동시에 통계와 확률에 대한 개념을 강화하는 좋은 기회가 되는 것 같습니다. 또한, 데이터 시각화는 복잡한 데이터의 관계를 명확하게 이해하는 데 도움을 주며, 머신러닝 모델을 통한 예측은 수학과 과학적 사고를 실생활 문제에 적용하는 방법을 보여줍니다. 무엇보다, 캔디라는 주제는 학생들에게 친숙하고 흥미로우면서도, 데이터 과학의 핵심 개념을 효과적으로 전달할 수 있는 매개체가 되는 것 같습니다.
오렌지3 재미쪄용~