
FIFA 데이터 군집화
FIFA 데이터
2015년부터 2022년까지의 FIFA 축구 선수에 대한 데이터로 국적, 클럽, 생년월일, 급여, 키, 몸무게 등과 같은 플레이어 개인 데이터와 Club Position, Ball Control, Strength와 같은 속성을 갖는 활용도 높은 데이터입니다.

군집화란?
군집화(Clustering)는 정답이 없는 데이터로 학습을 하는 비지도 학습(Unsupervised Learning)의 한 형태로, 유사한 특성을 가진 데이터를 같은 그룹으로 묶는 작업을 의미합니다. 각 군집의 특성을 해석해 봄으로써 군집화를 통해 데이터를 더욱 깊게 이해하거나 의사 결정을 지원할 수 있습니다. 군집화는 기업에서 개별 소비자나 기존 고객의 데이터를 바탕으로 고객 마케팅 전략을 수립할 때 사용할 수 있습니다.
군집화의 주요 알고리즘
1.
K-Means Clustering: 가장 널리 사용되는 군집화 알고리즘 중 하나로 K개의 클러스터를 형성하며, 각 데이터 포인트는 가장 가까운 중심점(Centroid)에 할당됩니다.  오늘 사용하는 알고리즘
오늘 사용하는 알고리즘
오늘 사용하는 알고리즘2.
Hierarchical Clustering: 트리 형태의 계층적 구조를 만들어 나가는 군집화 방법
3.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise): 밀도 기반의 군집화 방법으로, 특정 공간 내 데이터 밀도가 높은 부분을 클러스터로 묶음
오렌지3를 이용한 군집화 과정
1. 데이터 전처리
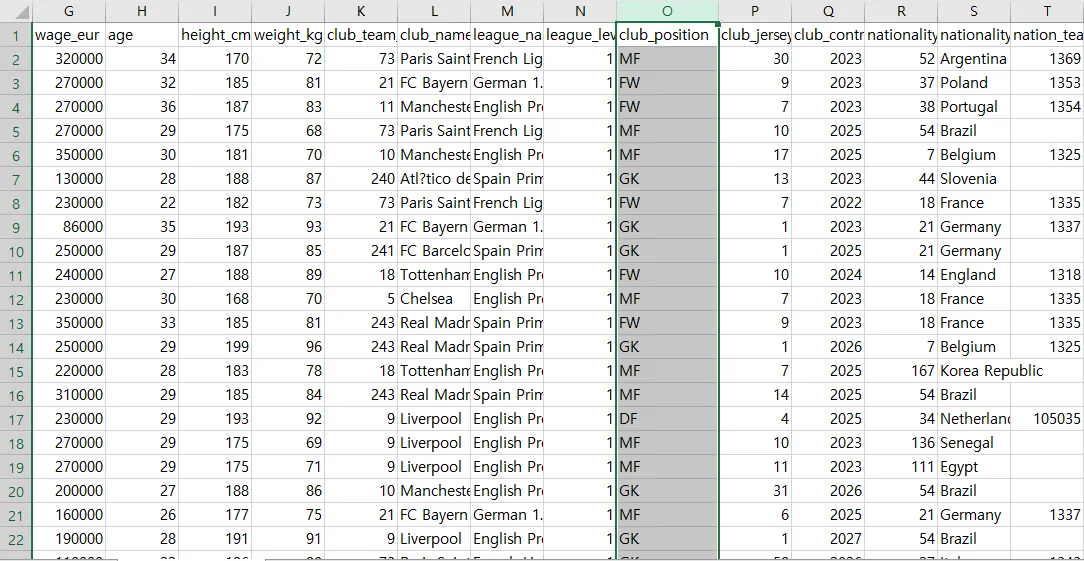
파일 다운로드 우선 22년도의 플레이어 데이터를 열어 각 속성이 어떤 값을 갖는지 의미를 파악합니다. 드리블과 체력과 같은 능력에 대한 수치 데이터를 위주로 군집화를 진행하기 위해 플레이어 URL과 플레이어 해시태그, 생년월일 등 군집화에 불필요한 열은 제거하였습니다.
또한, 미드필더(MF)가 수비형 미드필더(DM), 공격형 미드필더(AM), 윙어(RW/LW) 등으로 세분화되어 있는 것을 보고 학습자 수준에 맞는 실습 진행을 위해 미드필더(MF)로 바꿔주었습니다. (공격수(FW), 수비수(DF)도 세분화 되어 있어 동일하게 바꾸어 주었습니다^^) 최종적으로 club_position은 FW(공격수), MF(미드필더), DF(수비수), GK(골키퍼)의 네 가지 범주 값을 갖게 되었습니다.
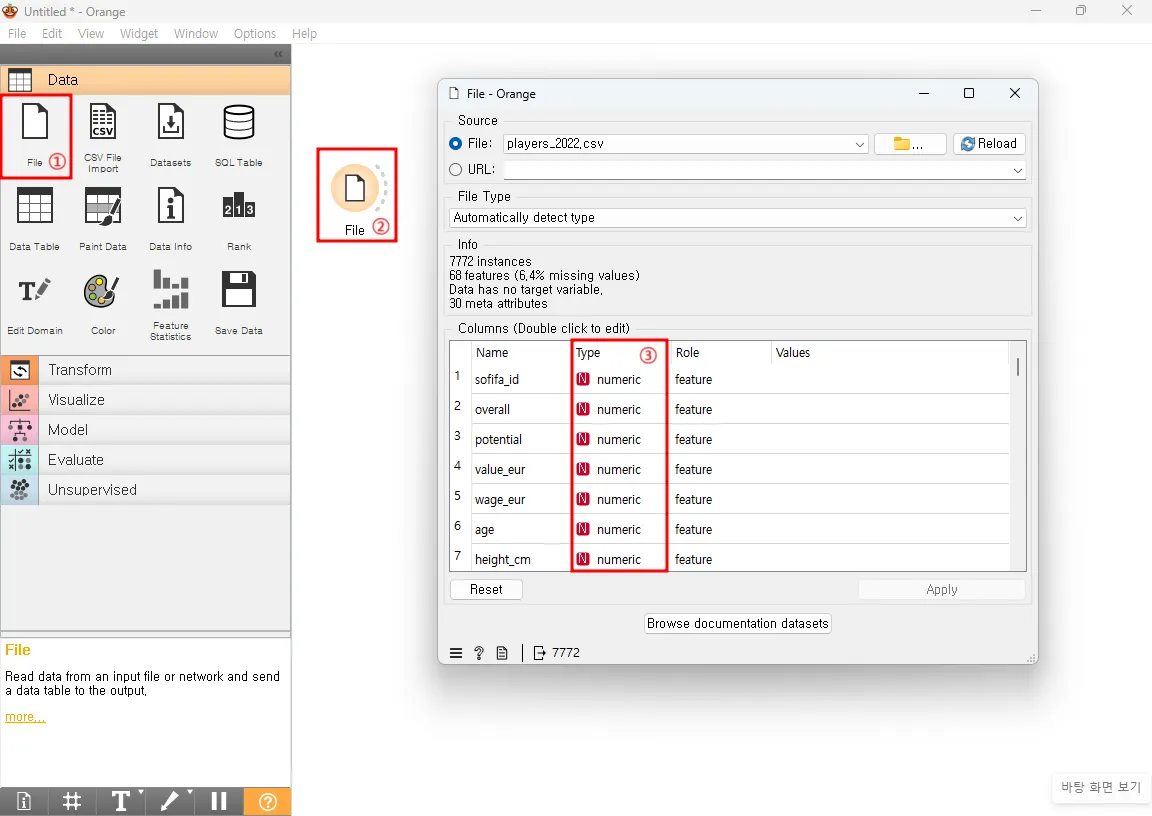
2. 데이터 불러오기
File 위젯을 클릭해 데이터를 불러오고 각 속성의 데이터 타입을 확인합니다.
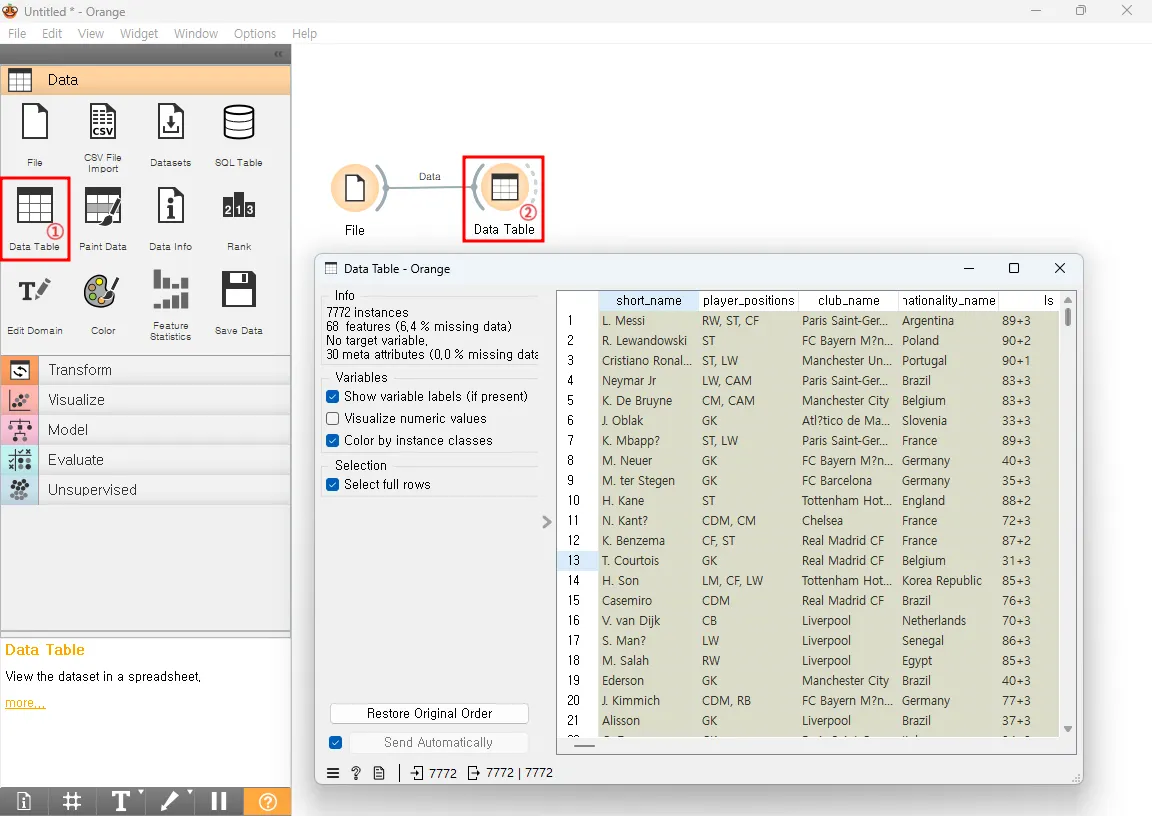
Data Table 위젯을 통해 불러온 데이터를 확인할 수 있습니다.
3. 군집화
이제 군집화를 진행해 볼까요? Unsupervised 메뉴에 K-Means 위젯을 가져와 File에 연결합니다. 오른쪽에서 군집의 개수(Number of Clusters)를 정해줄 수 있는데요. 군집의 개수를 원하는 값으로 고정하고 싶다면 Fixed를 사용하고, 특정 범위를 입력하여 최적의 군집 개수로 군집화를 진행하려면 From ~ to ~를 사용합니다. 사진에서는 2 이상 5 이하로 범위를 주었는데요. 실루엣 스코어(Silhouette Scores) 값이 가장 높은 2가 최적의 군집 개수라는 것을 알 수 있습니다.
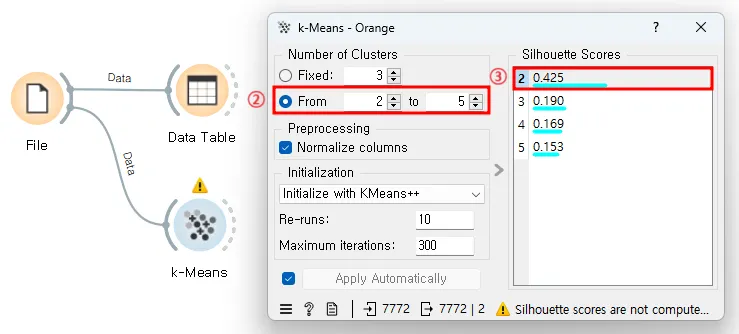
실루엣 스코어(Silhouette Scores)
군집화의 품질을 평가하는 지표 중 하나로, 이 값은 -1부터 1까지의 범위를 가진다. 높은 실루엣 스코어는 군집 내의 데이터 포인트들이 서로 가깝고, 다른 군집과는 멀리 떨어져 있다는 것을 의미한다. 즉, 높은 실루엣 스코어는 군집화가 잘 되었다고 판단할 수 있는 기준이 된다.
오렌지3에서는 데이터 표본이 5000개가 넘어가면 실루엣 스코어가 계산이 되지 않습니다.K-Means 위젯에 Data Table을 하나 더 연결하면 각 데이터가 어느 군집에 속하는지 표로 볼 수 있습니다. 그림을 보면 각 선수들이 군집 C1과 C2에 할당이 된 것을 확인할 수 있습니다.
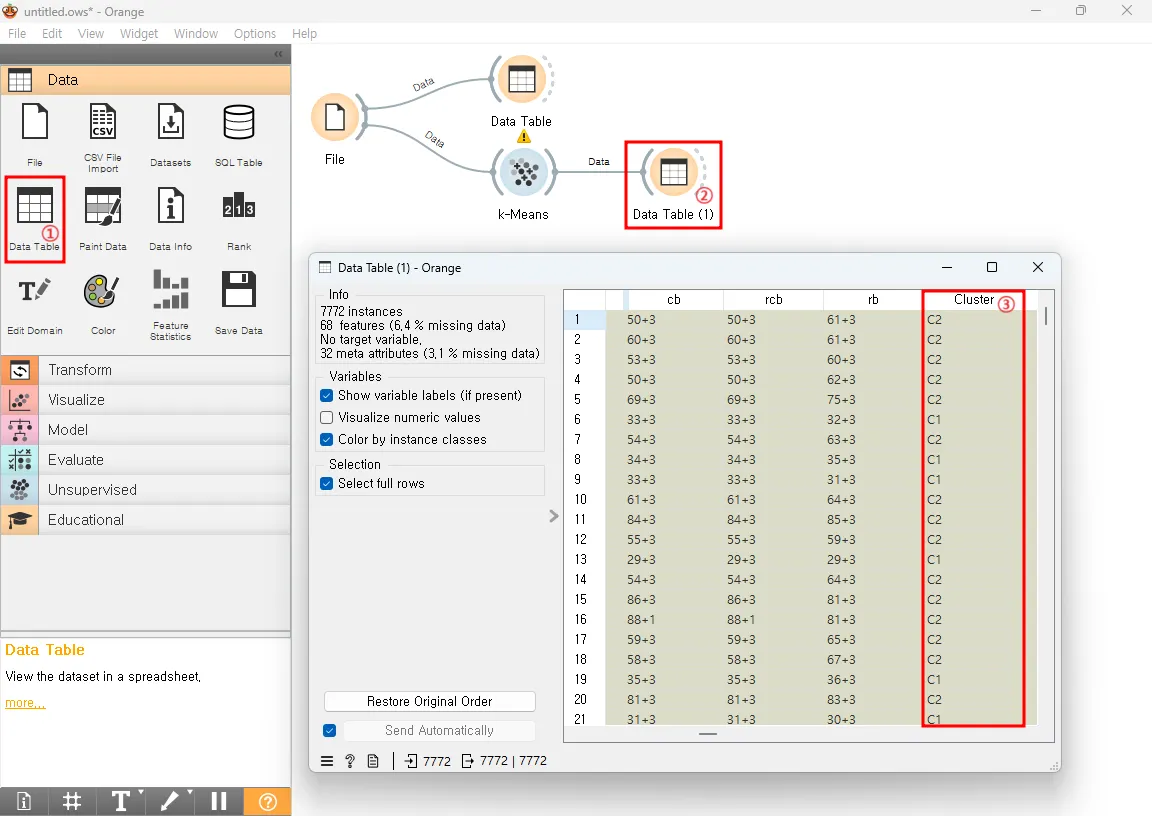
그럼 두 가지 위젯을 더 연결해 보겠습니다.
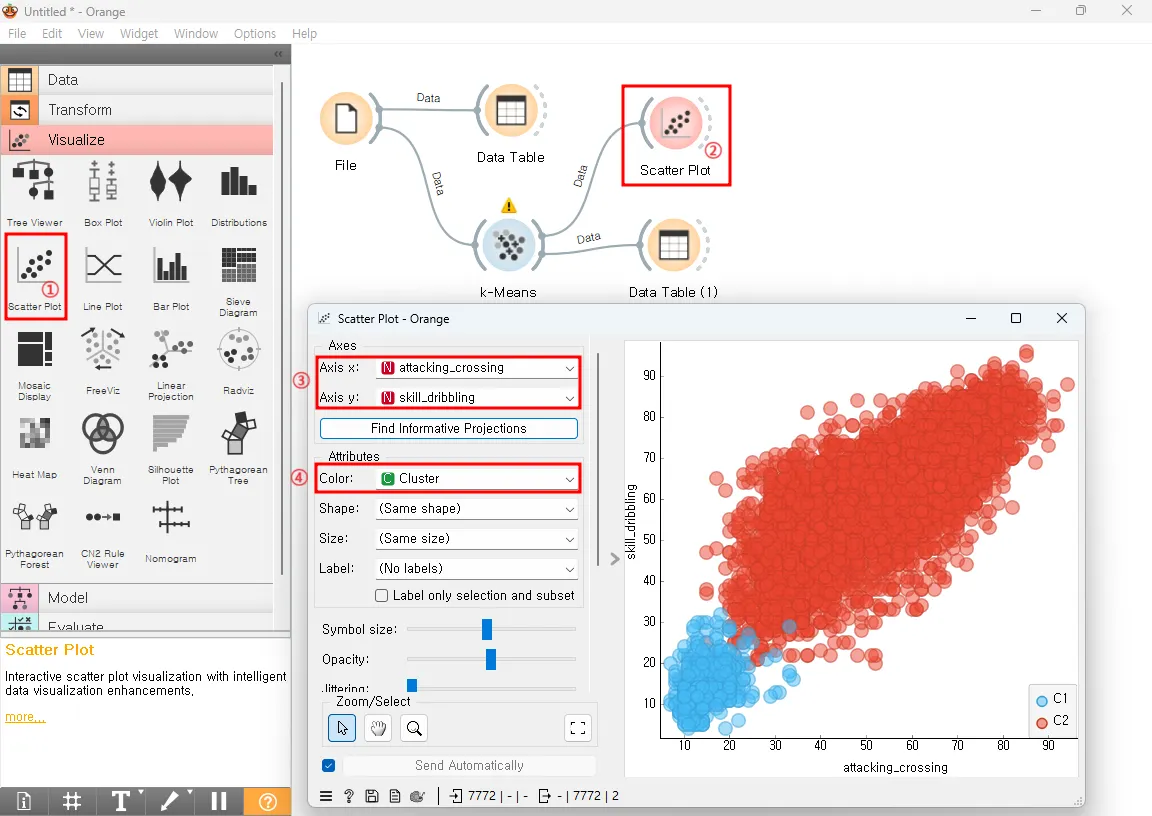
Visualize에 Scatter Plot 위젯을 연결하면 속성에 따라 그 값을 산점도로 표시한 후 나누어진 군집을 효과적으로 확인할 수 있는데요. 아래 그림처럼 x축은 attacking_crossing, y축은 skiil_dribbling으로 설정하고, color 속성을 Cluster로 설정해 주면 attacking_crossing와 skiil_dribbling 값이 낮은 그룹은 C1, attacking_crossing와 skiil_dribbling이 높은 그룹은 C2로 나누어진 것을 확인할 수 있습니다.
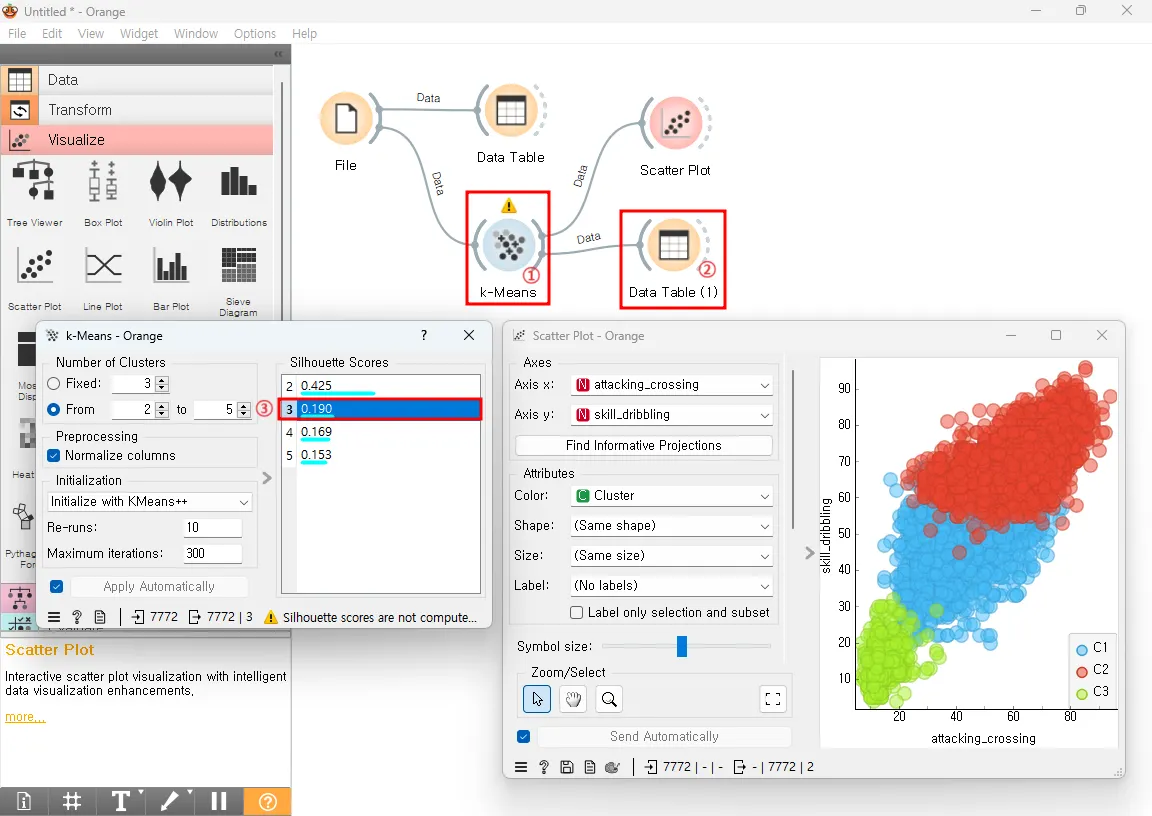
아까 보았던 K-means와 Scatter Plot창을 동시에 띄우면 군집의 개수를 조정해 가며 동시에 산점도의 모습을 확인할 수 있습니다. 아래 그림은 군집의 개수를 3으로 했을 때의 Scatter Plot 화면입니다.
마지막으로 Box Plot 위젯을 하나 더 연결해 보겠습니다. Box Plot은 통계 정보와 분포를 시각적으로 보여주는 시각화 차트로 Subgroups를 Cluster로 설정하면 각 군집별로 어떤 통계 값을 갖는지 효과적으로 확인할 수 있습니다.
아래는 서브 그룹을 Cluster로, Variable을 club_position으로 설정한 그림인데요. 보시면 군집 C1, C2는 골키퍼인 선수와 아닌 선수로 나뉜 것을 볼 수 있습니다.
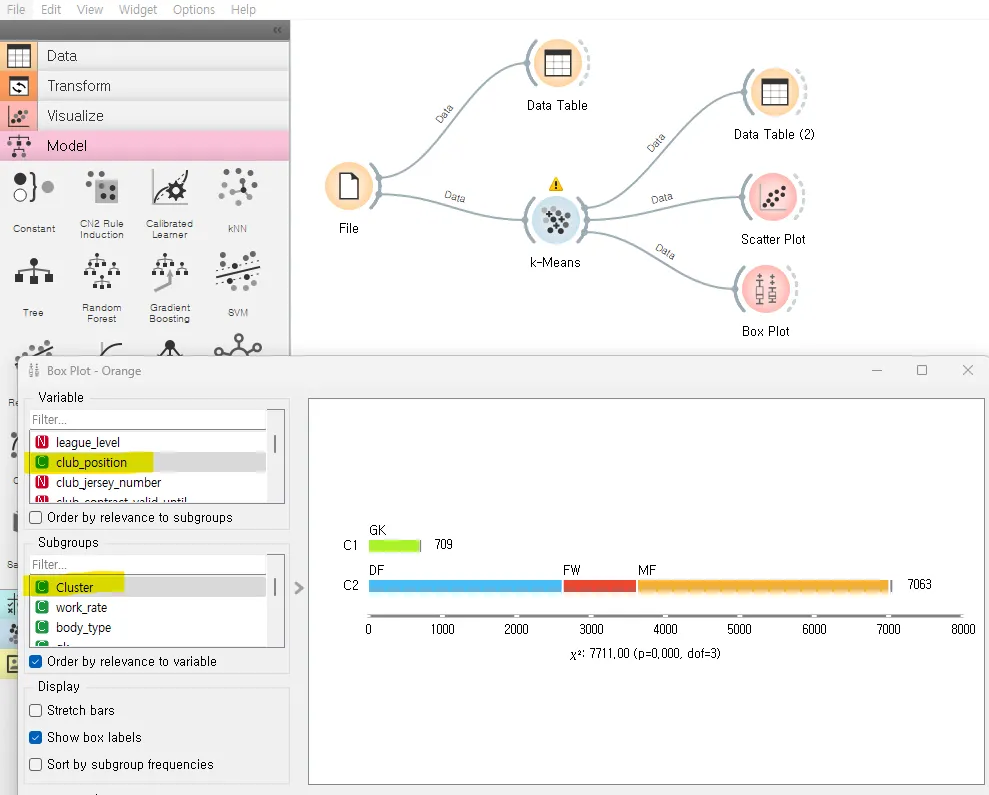
Variable을 바꾸어 차트를 살펴보면 여러 유용한 정보를 알아낼 수 있습니다. Variable을 power_stamina(체력)로 했을 때 C1, C2가 큰 차이를 보이지 power_jumping(점프능력)으로 했을 때는 두 군집의 차이가 크지 않은 것을 볼 수 있습니다.
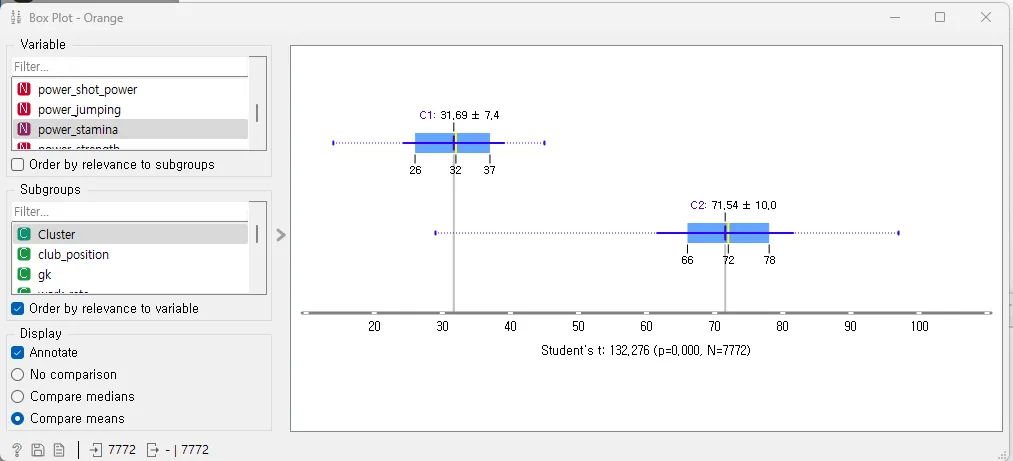
Variable : power_stamina
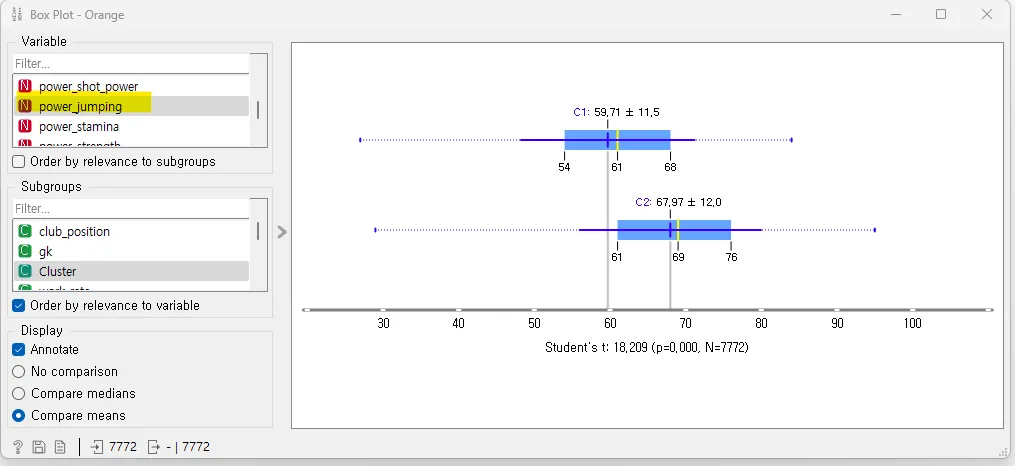
Variable : power_jumping
결론
군집화는 정답이 없는 비지도학습 중 하나입니다. 따라서 다양한 시각화 방법을 통해 군집의 특성을 직접 살펴보면서 원래 데이터에서는 알지 못했던 것을 발견하는 재미가 있습니다. 수업에서 군집화를 활용할 때도 학생들이 각 군집의 특성을 직접 파악하고 이를 이용하여 다시 지도학습을 적용해 보는 등의 실습에 활용할 수 있습니다.
위 실습에서도 골키퍼와 골키퍼가 아닌 축구선수가 명확하게 구분이 되기 때문에, 골키퍼를 제외한 데이터를 가지고 추로 군집화를 진행해 보면 미드필더, 공격수, 수비수의 특성을 파악하고 팀 구성, 전략 수립 등에 활용할 수 있습니다.
저는 수업에서 학생들에게 SNS 이용 패턴과 관련된 10개 문항의 설문지를 돌려 직접 학생들이 응답한 데이터 파일을 가지고 군집화 수업을 해본 적이 있는데요. 아이들과 결측치를 제거하고 형식에 맞지 않는 응답을 직접 수정해 보면서 전처리 과정도 같이 해보고, 군집화를 통해 내가 어떤 성향의 아이들과 같은 그룹인지, 속한 그룹의 성향이 어떤지 알아보는 실습이 정말 재미있었습니다
[한 걸음 더] K-Means 군집화 과정을 눈으로 확인해 보자!
오렌지3에서 K-Means군집화 과정을 시각화하여 확인할 수 있는 방법이 있습니다.
먼저 K-Means 알고리즘을 살펴보겠습니다.
K-Means 군집화 과정
K-Means에서 K의 의미는 묶는(군집, 클러스터) 개수를 의미합니다.
군집의 개수에 따라 묶이는 결과도 달라집니다. means는 평균을 의미하여 군집의 중심과 데이터들의 평균 거리를 계산하여 군집화합니다.
1. 군집의 개수 설정
2. 초기 중심점 설정
3. 데이터를 군집에 할당하기(중심으로부터 모든 데이터의 거리를 계산하여 데이터에서 가장 가까운 중심을 지정)
4. 중심점 재설정하기
5.데이터를 군집에 재할당하기
군집의 중심점은 임의로 배정이 되어 시작되게 됩니다.
이러한 과정을 시각화하여 볼 수 있는 방법은 [Options] - [Add-ons]에 포함되어 있는 Educational을 설치하시면 가능합니다. Educational을 체크하고 OK를 클릭하면 자동으로 설치됩니다.
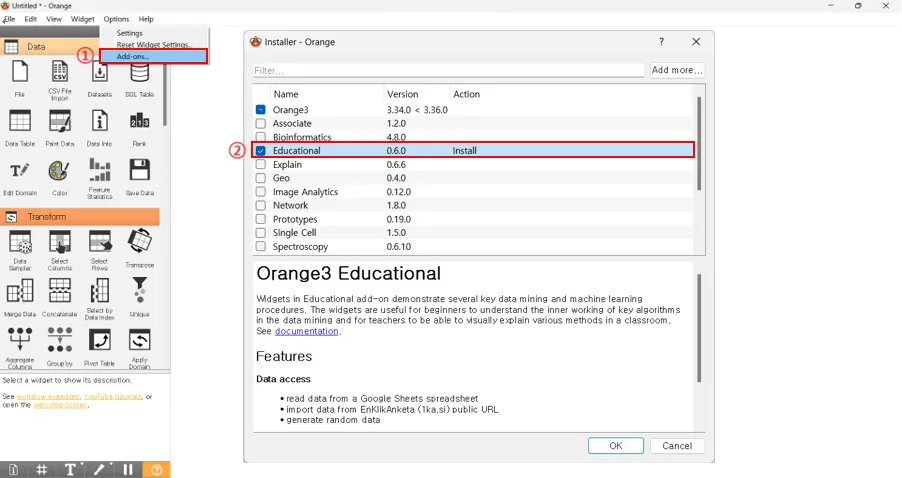
Educational 위젯은 주요 데이터 마이닝 및 기계 학습 절차를 보여줍니다.
K-Means, 경사하강법, 다항식 회귀, 다항식 분류를 시각화하여 제공하며, 오렌지3에서 제공하지 않던 원형 차트도 제작할 수 있습니다.
그중에서 K-Means의 과정을 시각화할 수 있는 Intrective K-Means 위젯을 사용해 보도록 하겠습니다.
위에서 전처리했던 데이터를 다시 사용하도록 하겠습니다.
File 위젯과 Data Table 위젯을 사용하여 데이터를 불러옵니다.
그리고 Interactive K-Means 위젯을 File 위젯과 연결합니다. 이렇게 하면 준비가 끝납니다.
위젯이 생각보다 너무 적어서 당황스러울 수 있지만 Interactiv K-Means 위젯을 더블 클릭해 보시면 K-means 군집화 과정을 볼 수 있습니다.
처음엔 overall과 potential 속성으로 설정되어 있지만 이것을 위에서처럼 x축은 attacking_crossing, y축은 skiil_dribbling으로 설정한 뒤 k(중심점)의 수를 조정합니다.
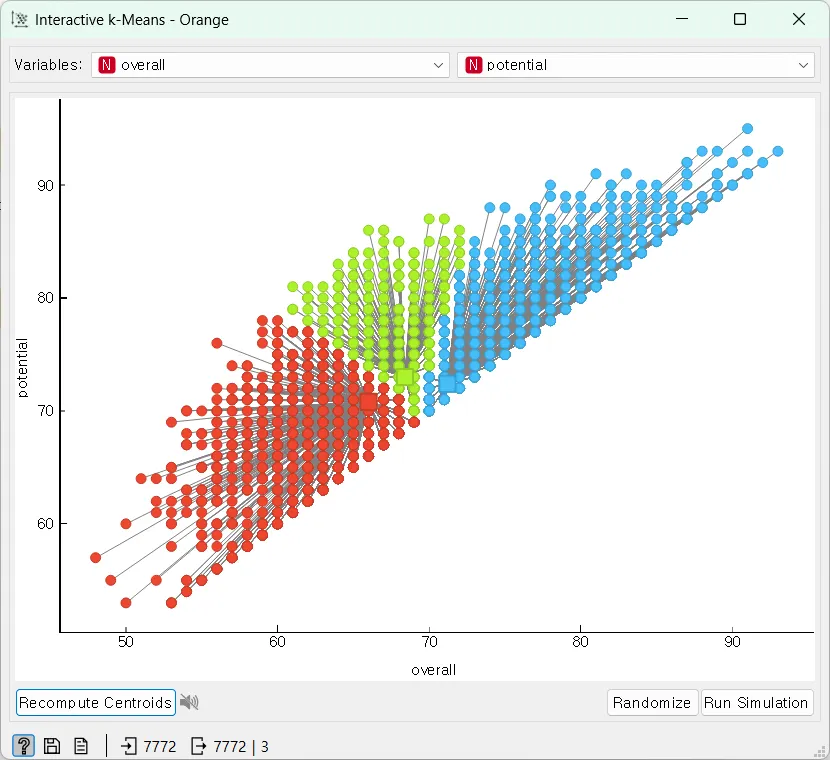
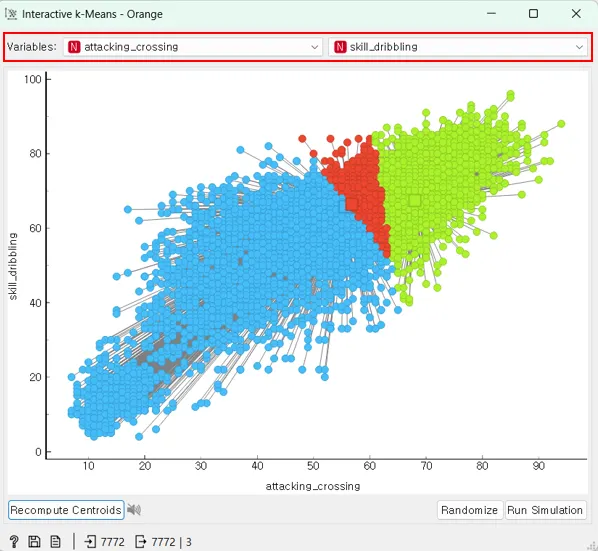
k(중심점)의 수를 추가하려면 원하는 곳을 클릭하면 자동으로 새로운 중심점이 추가되면서 군집이 생깁니다.
중심점을 삭제하는 방법을 알려드리겠습니다. 둥근점 사이에 보이는 네모점이 있는데, 네모점이 중심점이고 네모점을 클릭해주시면 됩니다.
중심점이 사라지게 되면 데이터들은 다른 군집에 속하게 됩니다.
[Randomize] 버튼을 클릭하여 중심점을 무작위로 선정할 수 있습니다.
버튼을 클릭할 때마다 중심 점이 무작위로 지정됩니다.
[Recompute Centroids] 버튼을 클릭하여 중심점을 무작위로 선정한 후 중심점을 다시 계산할 수 있습니다. 버튼을 클릭하면 중심점이 다시 설정됩니다.
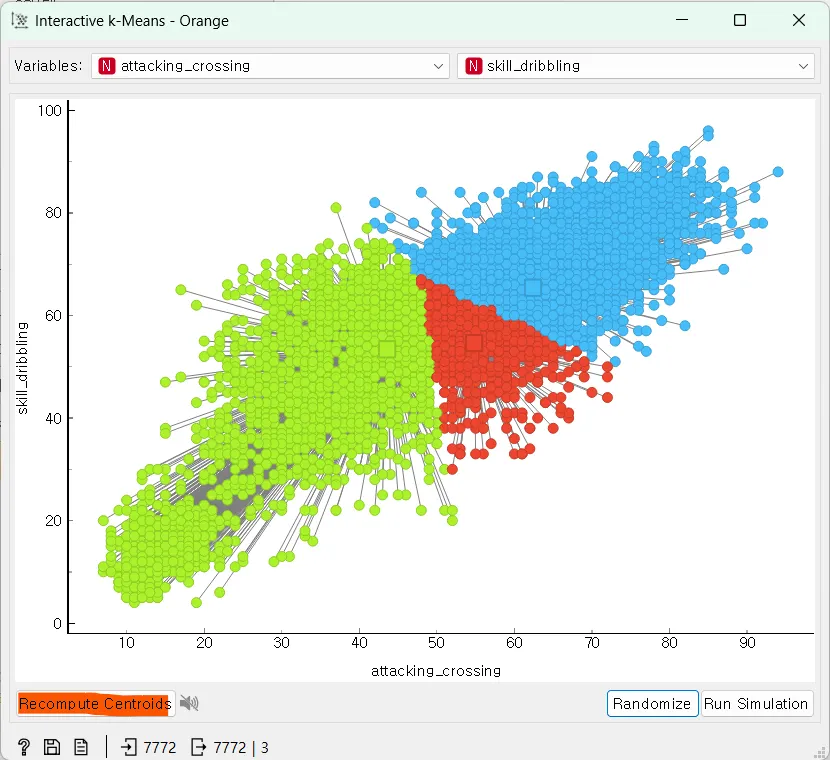
계속해서 중심점을 다시 계산할 수도 있고, 중심점이 이동하는 것을 확인할 수 있습니다. 또한 [Step Back] 버튼을 통해서 이전 상태로 되돌리는 것도 가능하다.
[Run Simulation] 버튼을 통해서 반복해서 중심점을 계산하며 중심점이 이동하는 것을 확인할 수 있습니다.
반복해서 중심점을 계산하다가 중심점의 움직임이 적어지는 것이 보인다면 군집화가 끝난 것입니다.
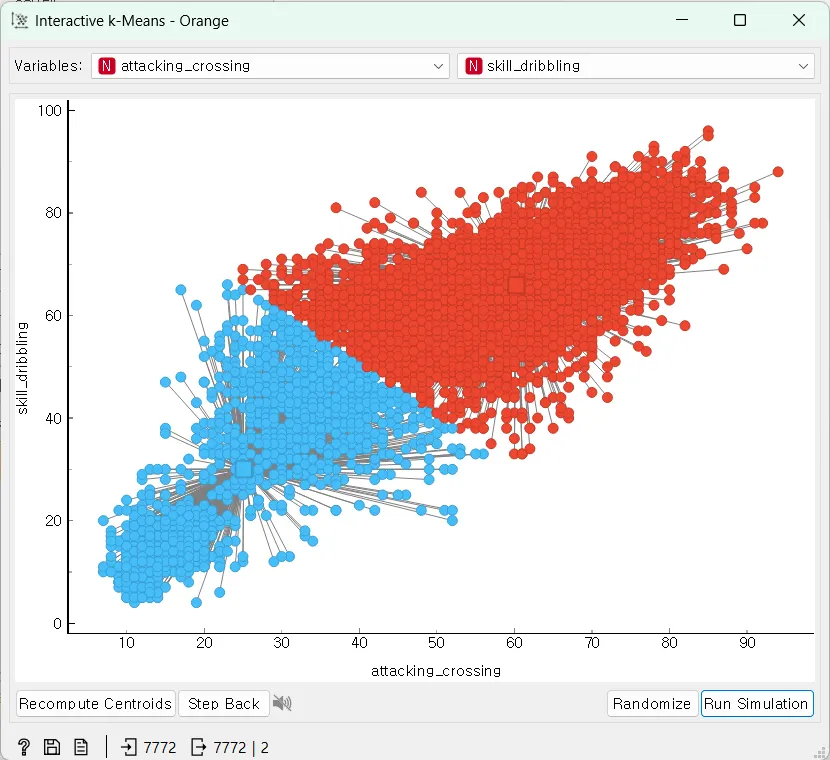
마지막으로 군집을 두 개로 설정하고 군집화를 해보도록 하겠습니다.
attacking_crossing 과 skill_dribbling의 결과는 위에 결과와 다르게 나왔습니다.
이번엔 x축에 power_shot_power와 y축에 goalkeeping_diving으로 군집화해 보겠습니다. goalkeeping_diving속성은 GK 골키퍼에게 더 뛰어난 능력으로 골키퍼와 다른 포지션이 확연하게 군집화될 것입니다.
금방 군집화 되었습니다.
결과는 K-Means 위젯을 활용하여 군집화한 것과 같은 것을 확인할 수 있습니다.
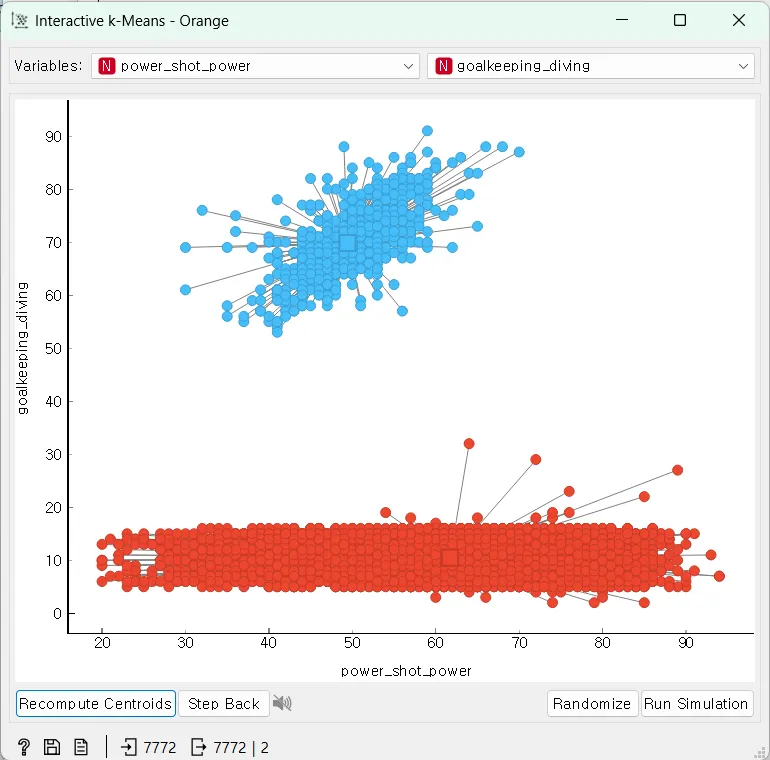
Interactive k-Means 위젯의 결과
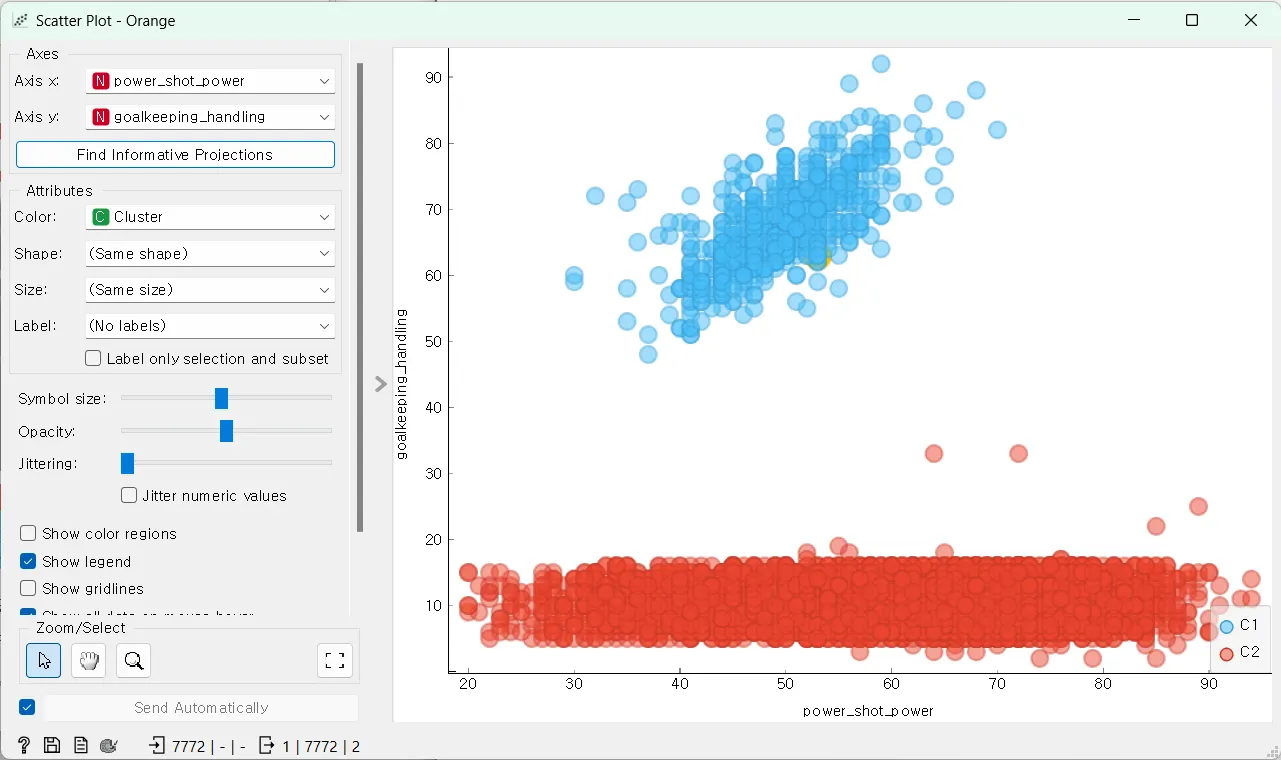
K-Means 위젯의 결과
결론
군집화의 결과뿐만 아니라 과정까지 학생들과 확인할 수 있기 때문에 K-Means 위젯과 Interactive K-Means 위젯을 함께 학생들에게 제공한다면 K-Means 군집화 알고리즘에 대해서 학생들이 학습할 조금 더 쉽게 이해할 수 있을 것 같습니다~~^^